




-
当前人工合成化学物被大量生产使用,给食品安全风险评估带来严峻挑战. 传统的化学物风险评估数据主要依赖于动物试验及体外试验等各类测试方法,但测试成本、试验周期、动物伦理以及“3R”原则的限制,导致了无法开展高通量、快速的风险评估. 随着毒理学测试方法的发展和风险评价策略的调整,2007年美国国家研究委员会提出“21 世纪的毒性试验:愿景与策略”(Toxicity Testing in the 21st Century: A Vision and a Strategy),强调了未来化学物毒性测试应借助计算毒理学和基于人源细胞、细胞系或细胞组分体外测试的组合方法[1],即新策略方法(New Approach Methodologies,NAMs),包括我国在内的很多国家和国际组织正在开展下一代风险评估技术研发[2 − 5],而NAMs是下一代风险评估的技术支持.
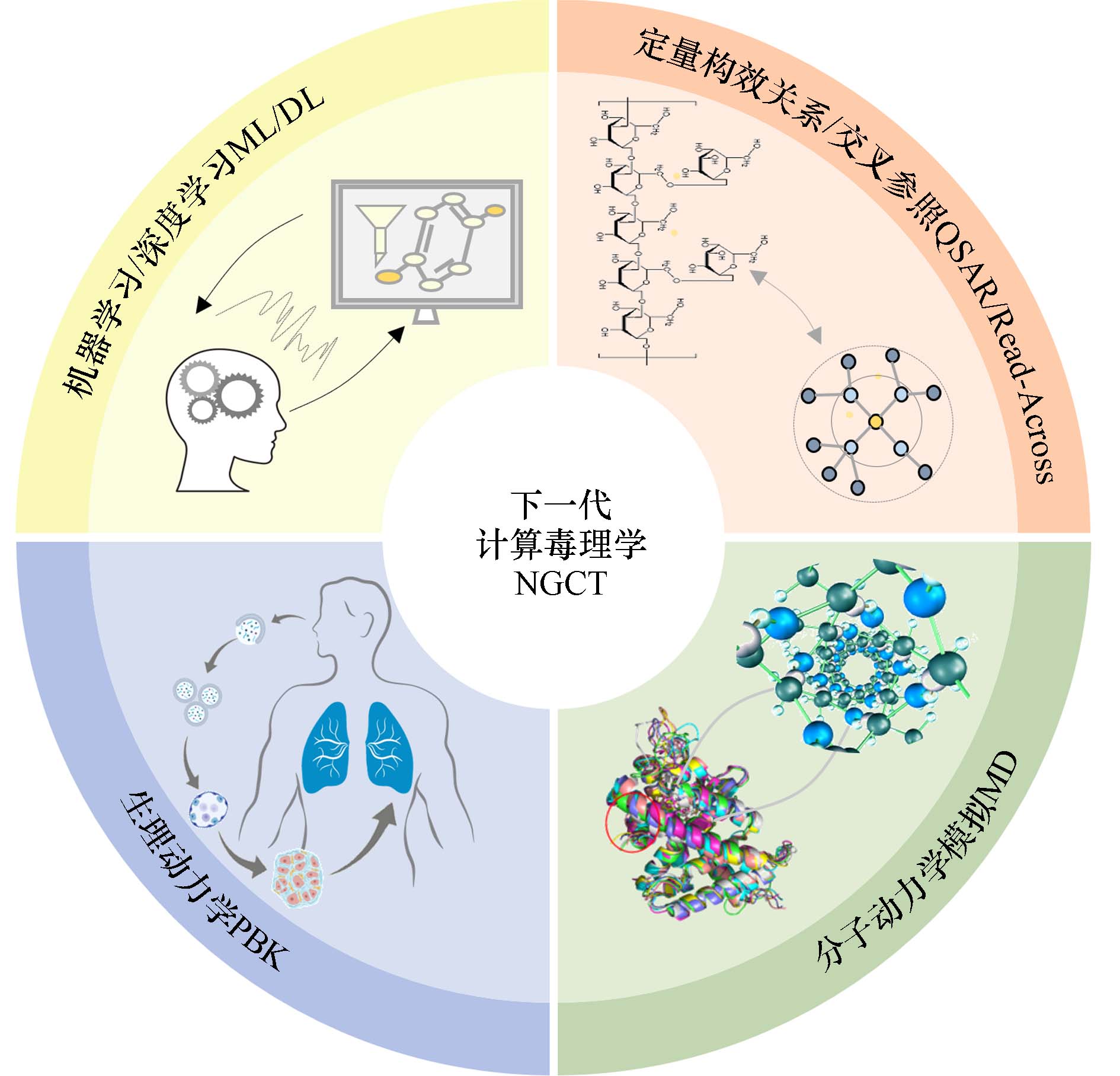
随着人工智能(Artificial Intelligence,AI)的快速发展,基于机器学习(Machine Learning,ML)和深度学习(Deep Learning,DL)的下一代计算毒理学(Next-Generation Computational Toxicology,NGCT)逐渐兴起(图1),为化学物的高通量测试提供技术支撑[6]. NGCT通过挖掘化学、毒理学、医学、多组学、系统生物学等在内的多模态大数据,对化学物的各类属性以及毒性等进行高通量预测. 目前NGCT被逐渐用于开发化学物风险评估的NAMs[7],美国食品和药品管理局关于建模和仿真的相关报告中重点强调了NAMs的应用,如基于生理的动力学模型(Physilogically Based Kinetics,PBK)建模、定量构效关系(Quantitative Structure-Activity Relationship,QSAR)分析、交叉参照分析(Read Across)用于风险评估的概率和统计建模等. 为进一步促进NGCT在化学物风险评估中的应用,本文介绍NGCT主要方法及其在食品安全风险评估中的应用,为化学物安全风险评估研究提供借鉴.
-
ML和DL在食品安全领域具有多种用途,常被用于预测食品安全风险. 随着AI的快速发展和大型数据库的建设,基于ML和DL的预测方法整合了多种NAMs,在化学物风险评估中发挥重要作用,近年关于机器学习的食品安全风险评估研究论文数量持续增加(图2).
ML和DL模型被广泛用于食品及食品相关化学物的安全性评估[8],可用于构建针对外源性化学物暴露的毒性筛查模型,包括贝叶斯网络[9]、神经网络[10,11]、支持向量机[12]和决策树[13,14]等算法常被用于食品安全风险分析及预警. 针对食品添加剂的潜在神经毒性,基于神经网络的ML模型建立了通用的食品有害因素分类评估分数,为大规模进行食品中具有神经毒性物质的风险评估提供有效手段[15]. 基于DL开发的DeepCarc模型运用碱基分类选择策略,实现了高准确率的化合物致癌风险优先级的筛选[16]. 通过亚临床和癌症前期阶段获得的数据构建ML模型,将有助于建立与饮食和儿童患传染性单核细胞增多症的关联,确定食品加工过程中产生的具有不良作用的化合物摄入的风险阈值[17]. 针对食品及食品添加剂的危害水平预测,将基于膳食暴露评估和暴露限值建立的风险评估模型,以及熵权-层次分析法计算食品中化学成分的风险值,进一步利用反向传播神经网络建立安全风险预警模型,预测食品的生产和加工过程是否存在安全风险,从而从源头上进行管控.
AI可结合电子鼻、电子舌、气相色谱-质谱、质谱代谢组学技术等检测方法,用于食品安全质量分析,特别是食品中特定成分或污染物的追踪[18]. 基于贝叶斯框架的稳定同位素混合模型通过建立同位素指纹、化学指纹等分析食品样品中的稳定同位素比例,实现食品中痕量污染物的溯源. 基于神经网络的稳定同位素混合模型,可以预测出不同品种、产地蜂蜜的地理来源,准确率达90%以上[19]. 针对食品中痕量或微量的化学残留分析,稳定同位素混合模型结合质谱分析技术可检测食物中的残留农药和未公开的添加剂[20],并对其空间分布进一步预测[21],这为食品添加剂的监管提供了技术支撑.
-
QSAR是基于化学物分子结构与生物活性/毒性建立的定量关系(图3). 数据集及分子特征描述的限制导致QSAR模型的应用域及泛化能力有限[22],而基于ML/DL的QSAR模型能够完全由数据驱动,数据量越大,模型的预测能力越强. 随着高通量试验的快速发展,大量的测试数据可用于训练深度QSAR模型[23].
随着AI的快速发展,围绕受体相关的关键分子靶点,利用化学物与受体分子交互作用的数据信息,可构建基于ML的QSAR模型[24]. 目前,基于ML/DL的QSAR模型已经用于食品-药物相互作用[25]、受体的结合活性[26-27]、肝脏毒性[28]及其他多种毒性终点的预测[29-30],在食品安全风险评估中显示出巨大应用前景.
ML/DL及QSAR模型常在数据量充足时表现出良好的预测性能,当化学物数据不足时,通常采用Read-Across作为数据缺口填补方法,用于预测目标物质的相同终点[31]. 基于ML的Read-Across工具能够估计所选结构特征的相关性[32],实现小型数据集上的高准确率预测效果. 将Read-Across集成到基于ML的QSAR模型中,通过数据融合为每种化学物质构建基于相似性的大型特征向量,结合QSAR和Read-Across的优点,使用多种相似性规则进行计算和加权,提高了模型的预测效率、可靠性和可解释性[33]. 如定量跨结构活性关系模型,使用最小二乘法消除了描述符之间的关联,且采用了ML方法对超参数进行优化,实现了高准确度的化学物心脏毒性预测[34]. 基于ML的Read-Across方法有助于解决相似性假说的不确定性,提高论据的充分性和可靠性、判断证据权衡结果是否明确已被广泛应用于化学物风险评估[35].
-
分子动力学(Molecular Dynamics,MD)模拟用于识别化学物质和生物大分子间的动态分子交互作用,为化学物风险评估提供更为全面的相互作用信息[36]. 分子模拟技术由于受到计算资源和算法的限制,精度和效率通常难以兼得,而将ML模型引入到分子动力学模拟中,能够在满足第一性原理精度的同时,计算速度媲美经验式模型,满足快速、低成本且高通量的预测要求(图4).
研究污染物与受体的交互作用有利于从蛋白质分子水平识别分子起始事件(Molecular initiation events,MIE),有利于深入了解MIE、关键事件(Key events,KE)和有害结局(Adverse outcome,AO)的关联,促进深入了解污染物毒性作用机制. 基于ML/DL的蛋白质-配体相互作用预测目前已显示出巨大的潜力[37]. 基于图学习的自适应机器能够适应多类数据集,比传统的分子动力学模拟展现出更好的预测性能[38];基于X射线结构中蛋白质-配体相互作用信息,利用六种图神经网络算法构建的模型准确预测了配体的亲和力[39]. 目前,AlphaFold 3模型在蛋白质-配体相互作用方面的预测性能皆优于其他传统分子模拟方法,能够预测包括蛋白质、核酸和小分子及多种复合物的结构,为化学物和受体相互作用研究提供更加准确全面的受体结构信息. 通过基于ML的原子间相互作用建模对食品成分及添加剂中的分子进行精确模拟,有利于预测由外源化合物暴露导致的内源性小分子的相互作用以及对人体健康的潜在影响[40].
随着大规模计算资源的持续增加,针对大量化学物开展MD模拟逐渐普及[41]. 基于分子交互作用信息,加强多模态数据扩充,构建融合MD重要特征的ML/DL预测模型,成为当前研究的新方法. 强化ML和MD领域之间的联合应用,构建集成式分子模拟及结构预测的综合性平台,将是人工智能与分子物理交叉领域荟萃方法的全新变革.
-
PBK模型可根据器官或组织内化学物及其代谢物浓度的时间变化,评估其在人体内的分布,模拟肝脏等代谢转化功能,提供毒物在体内的生物转化数据(图5). 在评估食品安全时,通过化学-生物相互作用的机理获得相关剂量-反应数据,借助PBK模型来预测人体体内的暴露量,最后进行风险表征.
PBK模型广泛用于预测特定人群通过食品摄入化学物质的暴露量,可预测化学物质在动物及人体内的分布和浓度,包括在血液、组织、乳汁等中的水平[42 − 44]. 欧洲食品安全局对食品中全氟烷基化合物对人类健康的风险进行评估时使用了PBK模型[42],能准确预测人类器官浓度-时间曲线、药代动力学行为和化学物的每日摄入剂量. PBK模型还能用于经由膳食摄入的化学物质到人体内浓度的推导[43],如预测乳汁中的化学物暴露,预测目标化合物的母体血浆暴露量和婴儿日摄入量[44].
传统的PBK模型受到动物试验伦理和低通量的限制,难以推广使用. 基于AI建模的下一代PBK模型克服了传统模型的技术瓶颈问题,可广泛应用于高通量化学物风险评估. 基于微生理系统的PBK模型用于皮肤-肝脏-甲状腺模型的开发,通过研究微流体循环连接的“器官”间的相互作用,预测几种典型的化学物在特定器官中的暴露[45],通过由皮肤和肝脏中的代谢及甲状腺激素表征化学物的生物效应. 与普通PBK模型相比,基于AI的PBK模型能够进一步预测器官水平的化学物质暴露,定性及定量描述化学物在体内的生物转化数据. 目前,通过使用计算机模拟、体外和人体生物监测数据对化学物的人体PBK模型进行细化和校准[46],极大促进从机制上理解食品安全风险,并提高预测结果的准确性.
定量危害表征依赖于对体外试验读数的解释,这需基于体外基准浓度将体外浓度-效应数据外推至体内剂量-效应数据,即定量体外-体内外推(Quantitative in vitro to in vivo Extrapolation,QIVIVE),通过体外组学数据预测体内毒性,区别于传统的动物实验,更加符合下一代风险评估的要求. 基于AI的PBK模型整合了关于化学物在人体或生物体中的吸收、分布、代谢和排泄的知识,成为体外-体内外推的有效工具,能够实现跨物种、途径和各种暴露情景预测[47]. 基于深度学习的Deep-PK模型能够识别影响化合物属性的关键分子区域,其在分子层面上的识别和预测性能远超常规的生理动力学模型[48]. 基于人工神经网络并融合化学物质文本描述和结构信息的多模态模型,能够实现同时预测不同物种、组织、测量方法和血液基质的组织-血液分配系数,为化学物内暴露评估提供了有效手段[49]. 将QIVIVE用于化学物的暴露,能够帮助深入理解化学物毒性的分子机制[50].
-
大量人工合成化学物被生产、投入使用并不断产生相关测试新数据,亟需为其开发通用的评估模型. 包括我国在内的很多国家和国际组织正在探索下一代风险评估方法,将整合有关分子系统生物学的信息纳入未来的风险评估范畴. NGCT将海量多模态数据有机整合,可实现对于化学物多种性质的高通量预测,揭示化学物质如何在生物体内引发不良健康效应,为食品安全风险评估提供深层次的机制性理解,能够推动化学物食品安全风险评估研究新范式的建立. 目前大语言模型(Large Language Model,LLM)在提取和整合高通量数据上表现突出,能够处理来自高通量筛选、组学、生物信息学和其他来源的大量复杂数据,其中垂直大模型能够专注于特定领域的数据处理和分析,通过自然语言处理技术更深层次地理解、整合并分析多模态数据,训练数据中的模式和关系,对新化学物的行为进行高精度预测,将促进化学物风险评估的变革性发展. 未来需要进一步结合LLM在自然语言处理、预测分析和决策制定方面的先进能力,提高风险评估的准确性和透明度.
下一代计算毒理学在食品安全风险评估中的应用
The application of next-generation computational toxicology in food safety risk assessment
-
摘要: 随着人工智能的迅速发展,基于机器学习和深度学习的下一代计算毒理学(Next-Generation Computational Toxicology,NGCT)逐渐兴起. NGCT通过整合化学、毒理学和系统生物学等多模态大数据,实现对化学物属性和毒性的高通量预测,克服了传统风险评估方法的局限性,推动了化学物的高通量风险评估. 本文总结了NGCT在融合分子交互特征、预测化学物属性和暴露数据、以及食品安全风险评估领域的应用. 鉴于大语言模型对研究新范式的推动,进一步展望了大语言模型在食品安全领域自然语言处理、预测分析和决策制定方面的潜力,并简述了基于NGCT的食品安全风险评估新范式.Abstract: With the rapid development of artificial intelligence, Next-Generation Computational Toxicology (NGCT) based on machine learning and deep learning is gradually emerging. NGCT integrates multimodal big data from chemistry, toxicology, and systems biology to achieve high-throughput predictions of chemical properties and toxicity, overcoming the limitations of traditional risk assessment methods and promoting high-throughput safety risk assessment of chemicals. This article summarizes the applications of NGCT in integrating molecular interaction features, predicting chemical properties and exposure data, and assessing food safety risks. Given the transformative impact of large language models (LLMs) on new research paradigms, the potential of LLMs in natural language processing, predictive analysis, and decision-making in the field of food safety is further discussed, and a new paradigm for food safety risk assessment based on NGCT is briefly described.
-
Key words:
- chemicals /
- food safety /
- computational toxicology /
- machine learning /
- high-throughput /
- risk assessment
-
磷(P)是现代农业和化学工业中广泛使用的重要资源,通常以磷酸盐的形式存在于水溶液中[1]. 然而,在磷化工的快速发展和过量施用磷肥下导致磷大量向淡水资源转移,水体磷浓度超标,藻类过度生长,引起水体富营养化,造成磷资源损失和环境污染[2 − 3]. 此外,磷是一种不可再生资源,由于每年对磷的需求不断增长[4],预计在未来100—400年内将完全消耗掉[5]. 因此,废水中磷的去除和回收对于缓解富营养化染和磷资源危机至关重要[6].
迄今为止,化学沉淀[7]、膜分离工艺[8]、生物处理[9]、阴离子交换[10]和吸附[11]等多种技术已被证明可以用于去除水体中磷酸盐. 而吸附法因其操作简单、效率高成本低、应用方便等优点,吸引了众多研究人员的关注. 已经发现多种吸附材料,如水和氧化铁[12]、多孔二氧化硅[13]和碳基材料[14]等,它们具有良好的吸附性,用于去除废水磷酸盐的吸附剂. 但相对而言,这些吸附剂多为粉末形式很难在水中回收,这可能会造成二次污染问题[15]. 并且一些材料存在苛刻的问题制备条件好,成本高,去除能力低,难以分离等缺点. 制备高效稳定、绿色环保可循环利用的新型磷酸盐吸附材料吸附和回收水体磷酸盐,这是近年来的研究热点之一[16].
近年来,合成纤维作为催化剂和吸附剂载体受到研究者的广泛关注. 其中,腈纶纤维(PANF)含有丰富的氰基和酯基等化学性质活泼的基团,在一定条件下可以进行特定的化学反应,并可以转化为具有多种官能团的新型功能化纤维,是一种优秀的载体材料. 腈纶纤维具有成本低、易获得、密度低、柔韧性好等特点,其在大规模机械化加工和环境保护方面也具有一定的优势[17]. 腈纶纤维可以在一定条件进行灵活改性,构建富含氨基、羟基、羧基、季铵盐等组分[18]. 例如,Xu等[19]通过简单的化学接枝反应合成了一种可回收的载铁胺化聚丙烯腈纤维(PANAF-Fe)去除废水中的磷酸盐;Zheng等[20]合成了富含氯离子的功能化聚丙烯腈纤维(PANAF-Cl),对废水中磷酸盐的去除率高达90%以上,最大吸附容量为15.49 mg·g−1. 丁天琦[21]以聚丙烯腈(PAN)作为基体,制备出多孔碳纳米纤维膜,对磷酸盐最大去除量可达131 mg·g−1.
铁、铜、镧等金属和磷酸盐具有较强的结合能力,其在水体磷酸盐的去除获得较多的应用. 然而,使用固载铜离子的胺化纤维对水中磷酸盐的吸附尚缺乏研究. 本研究以腈纶纤维为原料,将Cu2+固载在胺化改性腈纶纤维表面,制备了新型磷酸盐吸附剂(PANAF-Cu),探究了该吸附剂对水体中磷酸盐的吸附性能,为废水中磷的回收提供理论依据.
1. 实验部分(Experimental section)
1.1 试剂与仪器
腈纶纤维(抚顺石化公司,中国),使用前将其剪成长度约10 cm备用. 实验中所有化学试剂均为国内市售分析纯试剂,且未进一步纯化. 本实验中所用化学试剂:乙二胺、磷酸二氢钾(上海阿拉丁试剂有限公司)、三水合硝酸铜(上海麦克林生化科技股份有限公司);盐酸、硝酸、硫酸(西陇科技有限公司);碳酸钾、氢氧化钠、碳酸氢钠(上海素艺化学试剂有限公司);氯化钾、硫酸钾、硝酸钾、一水合柠檬酸(国药集团化学试剂有限公司)、乙二胺四乙酸二钠(EDTA,上海苏懿化学试剂有限公司)、氯化钠(上海中试化工有限公司). 本研究中的所有实验使用的皆为去离子水.
实验中主要用到的仪器为:集热式恒温加热磁力搅拌器(DF-101S),巩义市予华仪器有限责任公司;磁力搅拌器(84-1A),金坛区西城新瑞仪器厂;鼓风干燥箱(DHG-9070A型),常州海博仪器设备有限公司;pH计(FE20~standard),梅特勒-托利多仪器有限公司;循环水式多用真空泵(SHB-Ⅲ),郑州长城科工贸有限公司;分光光度计(722G),上海仪电分析仪器有限公司.
1.2 胺化腈纶纤维的合成
将600 mg干燥的腈纶纤维(PANF)、20 mL乙二胺和20 mL去离子水(DI)先在室温条件下混合搅拌,然后加入到高压反应釜中125°C反应100 min.反应结束后,将纤维从溶液中分离出来,后用70—80℃去离子水反复洗涤,再将纤维置于60℃烘箱中干燥过夜,得到淡黄色的胺化纤维(PANAF),即胺化腈纶纤维.
1.3 铜离子固载胺化腈纶纤维的设计合成
准备好50 mL 10 mmol·L−1的三水合硝酸铜(Cu(NO3)2·3H2O)配制的硝酸铜溶液,将50 mg干燥过夜后的胺化纤维加入到溶液中,室温下搅拌30 min,过滤后,进一步洗涤,反复冲洗,后将纤维放置在60 ℃的烘箱中干燥6 h,即可得到载铜的功能化纤维PANAF-Cu.
1.4 材料的表征
扫描电子显微镜(SEM,德国蔡司Sigma 300),傅里叶变换红外光谱仪(FTIR,美国PerkinElmer Spectrum One),全自动元素分析仪(EA,德国Vario EL Cube),X射线光电子能谱仪(XPS,美国Thermo Scientific K-Alpha),X射线衍射仪(XRD,德国Bruker D8 Advance),pH计(METTLER TOLEDO,FE20),可见分光光度计(722G,Shanghai).
1.5 铜离子固载腈纶纤维(PANAF-Cu)的表征
利用扫描电子显微镜(SEM)、元素分析(EA)、傅里叶红外光谱仪(FTIR)、X射线衍射光谱(XRD)和能量色散X射线谱仪(XPS)等表征功能化纤维的表面形貌、化学结构及内部晶体结构等,从而根据表征结果检验改性纤维是否初步制备成功.
1.6 吸附实验
分别探究不同吸附时间、不同pH值、不同温度以及不同初始磷酸盐浓度下PANAF-Cu对磷酸盐的吸附能力. 纤维吸附饱和后,用镊子将纤维吸附剂从溶液中分离出来,从剩余溶液中吸取1 mL溶液放入50 mL容量瓶中,后按钼酸铵分光光度法测定不同条件下待测液中磷酸盐的浓度,测定低浓度磷酸盐时,要先将剩余溶液用0.22 μm滤膜过滤,后使用ICP-OES测定. 所有吸附实验均进行3次重复. 计算吸附量和吸附率公式如下:
stringUtils.convertMath(!{formula.content}) (1) stringUtils.convertMath(!{formula.content}) (2) 式中,η为吸附率,%;qe为吸附P的量,mg·g−1;C0和Ce分别为无机磷初始质量浓度和平衡浓度,mg·L−1;V为溶液体积,L;W为吸附剂添加量,g.
1.7 吸附动力学
吸附动力学是用来描述吸附剂吸附溶质速率快慢的方式,采用拟一级动力学和拟二级动力学模型探究正在进行的吸附过程,以便讨论其合适的吸附机理. 不同动力学模型如下:
stringUtils.convertMath(!{formula.content}) (3) stringUtils.convertMath(!{formula.content}) (4) 其中, qt和qe为t时刻和平衡时的吸附量(mg·g−1)K1和K2依次为拟一级动力学和拟二级动力学的吸附速率常数.
1.8 吸附等温学
吸附等温线是描述在一定温度下吸附剂达到吸附平衡状态时吸附量(qe)和吸附质浓度(Ce)之间关系的曲线,常见的模型有Freundlich模型、Langmuir模型、Temkin 模型和D-R方程,本文采用Langmuir和Freundlich模型探究PANAF-Cu对无机磷的吸附方式,拟合方程如下:
stringUtils.convertMath(!{formula.content}) (5) stringUtils.convertMath(!{formula.content}) (6) 其中,qm为Langmuir模型估算的理论最大吸附量,KL为Langmuir常数,KF和n分别是Freundlich常数和均匀性系数.
2. 结果与讨论(Results and discussion)
2.1 功能化纤维(PANAF-Cu)的制备
固载铜离子的功能化腈纶纤维(PANAF-Cu)的合成由两步法完成,首先腈纶纤维和乙二胺发生胺化反应,纤维表面富含伯氨功能基的胺化纤维(PANAF),进一步利用氮和铜的配位作用,成功构建铜离子螯合的胺化纤维(PANAF-Cu). 胺化纤维的改性程度可以通过增重法来计算,胺化后的纤维对比腈纶纤维质量增加地较为明显,增重为10%,且纤维颜色也发生了变化,说明乙二胺被成功接枝到纤维表面. 胺化的程度可以通过控制反应时间或者乙二胺的浓度,过低的胺化程度不利于铜离子的螯合,然而过高的胺化程度导致纤维机械强度的下降,因此本文选择增重为10%的PANAF作进一步研究.
此外,本文研究了胺化纤维与不同浓度硝酸铜溶液制备得到的PANAF-Cu对磷酸盐的吸附能力, PANAF-Cu功能化纤维在Cu(NO3)2浓度增加的同时,其对磷酸盐的去除能力也不断增加,并且在Cu(NO3)2浓度为10 mmol·L−1时达到最高值,最大吸附量为35.29 mg·g−1. 然而,随着硝酸铜浓度的继续增加,PANAF-Cu中铜的含量达到饱和,导致其对磷酸盐的吸附能力趋势放缓至平衡,这是因为PANAF对铜的固载量是有限的,表明当铜离子浓度大于10 mmol·L−1时,PANAF对铜离子的固载量达到饱和. 因此,选择浓度为10 mmol·L−1的硝酸铜溶液制备PANAF-Cu.
2.2 功能化纤维(PANAF-Cu)的表征
2.2.1 纤维微观形貌分析
如图1可知,样品都呈连续完整的纤维状,表明纤维在改性前后及使用过程中,其完整性得到了良好的保持,未遭受到破坏. 放大2000倍的电子显微镜图像看到,随着改性反应的进行,纤维表面出现了若干裂纹,可能是因为氨基的进入和增溶作用导致纤维直径增加,出现裂纹,在一定程度上增加了纤维的表面积. 放大20000倍后,在胺化反应和螯合Cu2+后,可以清楚地观察到纤维不同程度的变形和溶胀,纤维表面明显变得粗糙,同时还被一层颗粒状物所覆盖,这可能是因为纤维表面的薄膜形成了由若干Cu-N配位产生的片晶.
2.2.2 纤维表面组分分析
为进一步明确纤维结构,利用傅里叶红外光谱(FTIR)和能谱图[22]分析了纤维改性前后的纤维表面组分. 图2(a)显示了每个阶段纤维的EDS能谱图,发现与PANAF相比,PANAF-Cu出现了新的Cu元素的峰,这表明Cu2+成功的固载到了胺化纤维上. 图2(b)显示了每个阶段纤维的红外光谱,PANF在2242 cm−1处的吸收峰和在1732 cm−1处的吸收峰分别为腈纶纤维第一单体丙烯腈的C≡N的伸缩振动和第二单体丙烯酸甲酯的C=O伸缩振动[17]. 由于胺化反应消耗了PANF上的氰基,胺化反应后2242 cm−1处的吸收峰强度下降. 此外,由于PANF中的C≡N在强碱性EDA溶液中被水解,与EDA中的NH2基团在1640 cm−1处形成了酰胺C=O双键的伸缩震动峰,说明了胺基基团的成功接枝[23]. 在胺化改性纤维吸附Cu2+后,在538 cm−1处新峰的出现,可能归因为Cu-N的配位结构,表明Cu已被-NH所固化[24]. 上述结果表明了胺基的成功接枝,以及Cu2+在纤维上的固载.
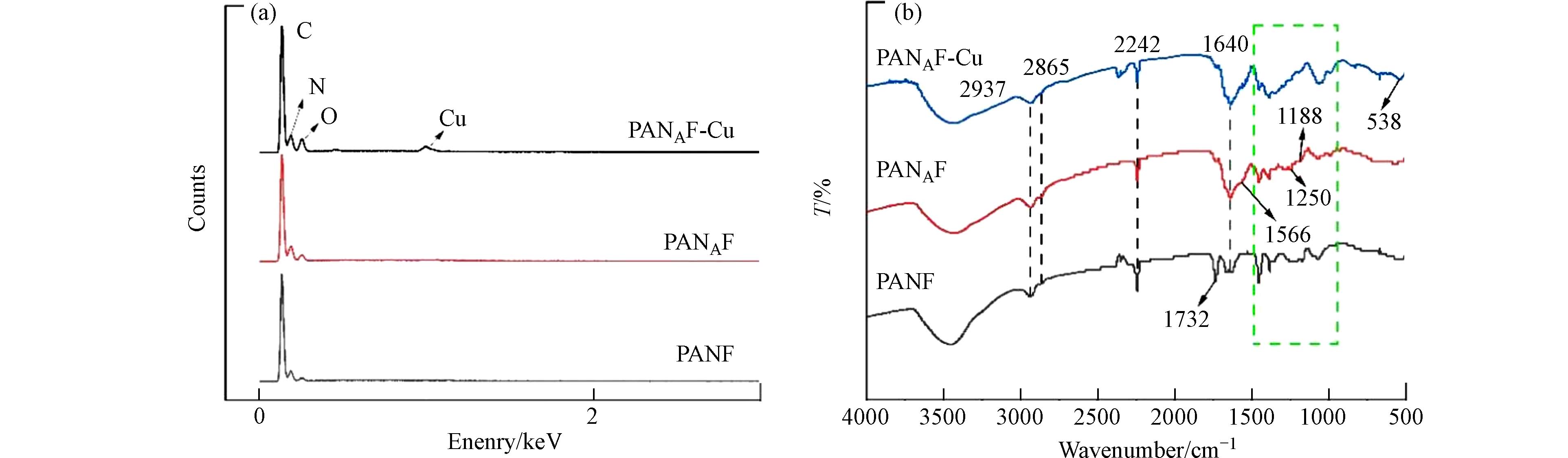 图 2 不同纤维的EDS能谱图(a) 和红外光谱图(b)Figure 2. EDS energy spectrum (a) and infrared spectra (b) of different fibers
图 2 不同纤维的EDS能谱图(a) 和红外光谱图(b)Figure 2. EDS energy spectrum (a) and infrared spectra (b) of different fibers2.2.3 纤维表面晶体分析
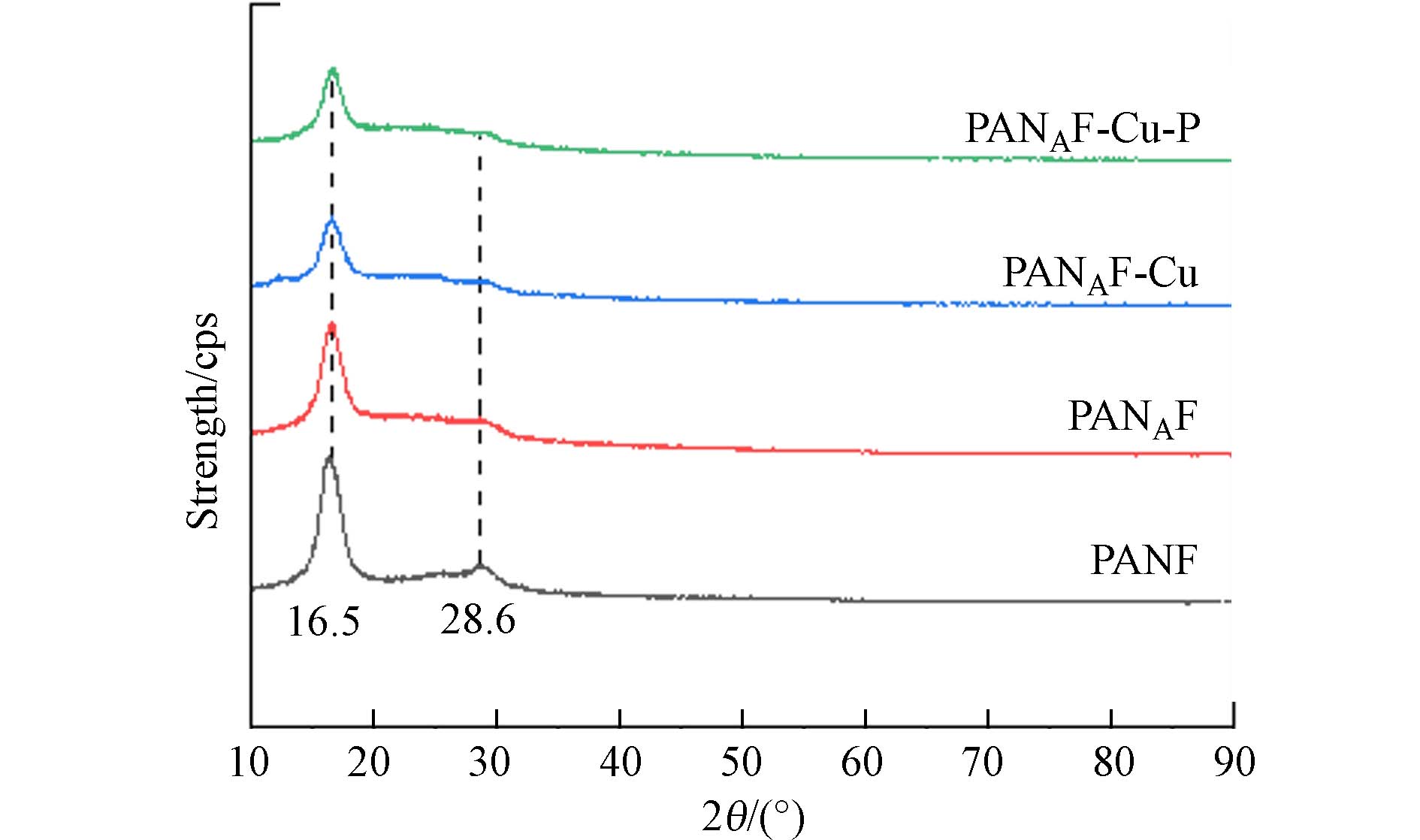
通过X射线衍射(XRD)表征了不同纤维的晶体结构. 图3显示了不同阶段的纤维的XRD图像,每个纤维都在2θ为16.5°处有一个共同的衍射峰,2θ = 28.6°处有一个不太强烈的衍射峰,表明PANAF、PANAF-Cu和PANAF-Cu-P与PANF具有相似的特征峰,表明纤维改性后仍保持了腈纶纤维原有的晶体结构,未被破坏,依然保持良好. 此外,PANAF、PANAF-Cu和PANAF-Cu-P较弱的衍射峰的强度明显降低,表明聚丙烯腈的聚合物链结构已经被胺分子部分溶解. 进一步固载Cu2+后,XRD光谱中并没有观察到结晶的Cu,这表明加载在纤维表面的固体Cu处于无定形状态,并可能通过Cu—N键与纤维骨架结合.
2.2.4 纤维元素含量分析
通过元素分析分析了不同阶段纤维的元素组成,相关数据见表1. 与PANF相比,PANAF中的C含量降低,H含量增加,因为乙二胺比原始腈纶纤维具有更少的C和更多的H,表明乙二胺被成功接枝到PANF上. 此外,N的存在也证实了不是所有的C≡N基团都被水解,参与EDA的官能化,所以改性过程可能仅发生在表面. 引入Cu元素后,PANAF-Cu中C、H含量的降低表明—NH2直接参与了Cu2+的吸附. 引入P元素后,相对于PANAF-Cu,PANAF-Cu-P中N含量的下降表明Cu与N形成配位键,被封存在纤维上,以上实验结果证明PANAF-Cu的成功改性.
表 1 不同纤维的元素分析数据Table 1. Elemental analysis data of different fibers样品Sample C/% H/% N/% 1 PANF 66.11 4.86 23.91 2 PANAF 60.30 5.89 22.77 3 PANAF-Cu 55.28 5.49 22.57 4 PANAF-Cu-P 55.76 5.65 21.91 | Show Table DownLoad:
CSV
DownLoad:
CSV
2.3 PANAF-Cu对磷酸盐的吸附性能研究
2.3.1 pH对 PANAF-Cu吸附磷性能的影响
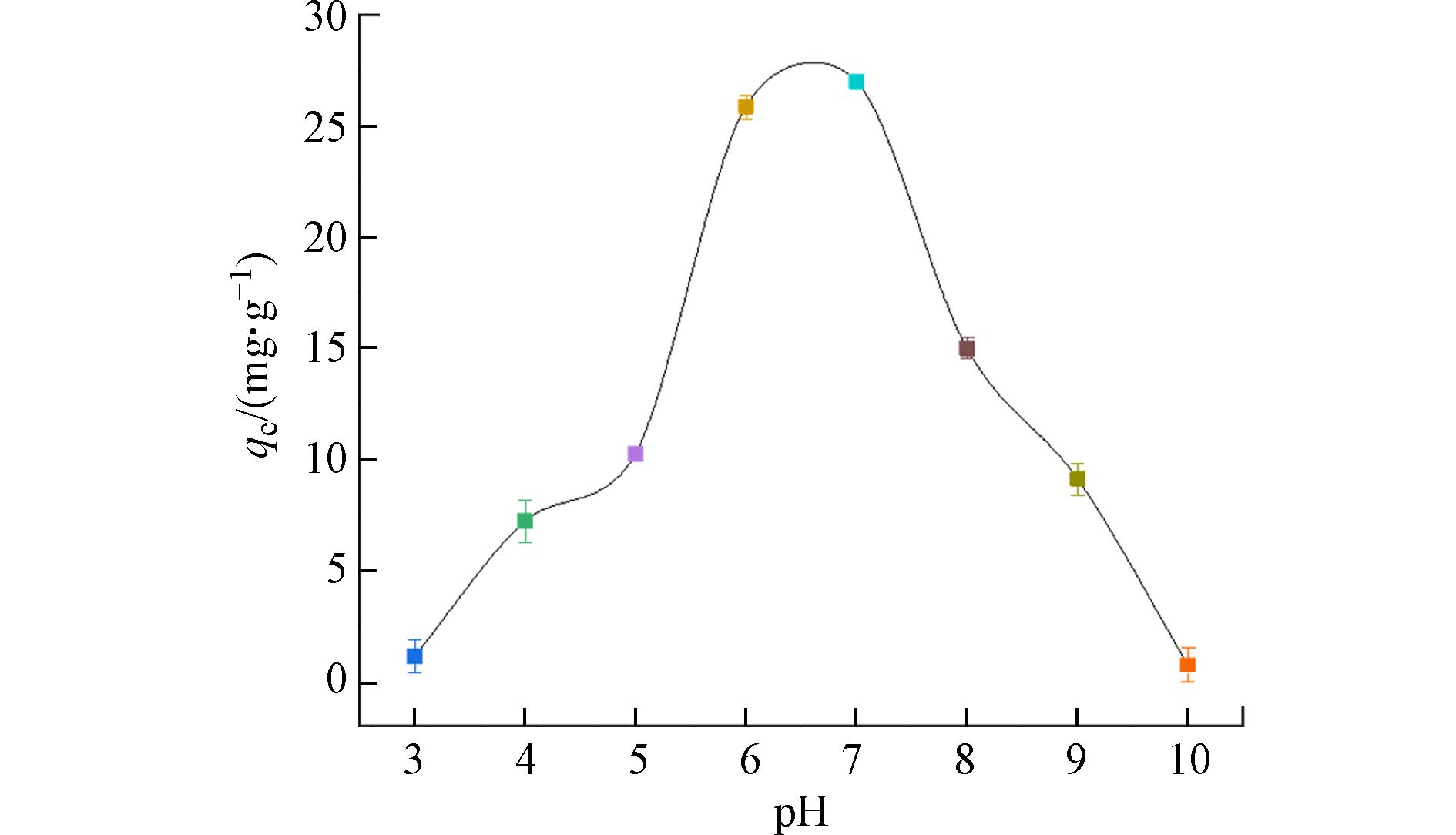
pH值是决定吸附效果的关键因素. 图4表明,pH值在3—7时,PANAF-Cu对磷酸盐的吸附量随着pH的升高而迅速增大,并在pH=7时达到最大值26.99 mg·g−1. 聚丙烯腈纤维的氨基的非选择性吸附是以静电作用形式产生的,因此,带正电的表面可以增强带负电的磷酸根阴离子的吸附. 其后通过配体的交换让表面负载的Cu2+对磷的进行选择性吸附. 在pH值在5—8的条件下,PANAF-Cu对磷酸盐的吸附量都能维持在较好的水平,吸附量仍能保持到10 mg·g−1以上. 表明固载铜离子的胺化改性纤维具有较高且稳定的磷酸盐去除效率.
2.3.2 吸附动力学分析
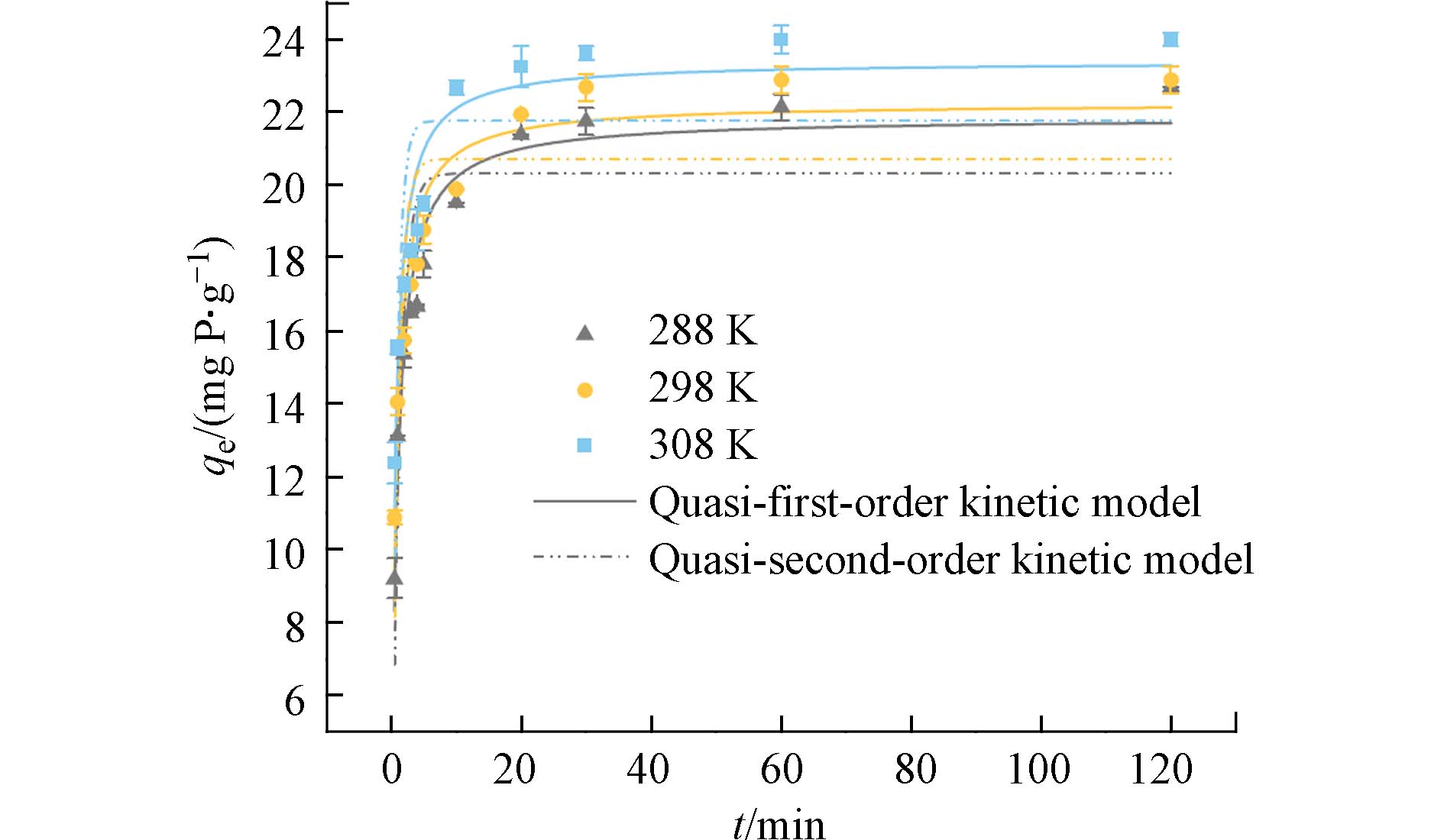
分别研究了在288、298 、308 K 的3种温度条件下,纤维吸附剂随时间改变对磷酸盐的吸附量的变化. 3条曲线的变化趋势大致相同,前10分钟内吸附速度较快,随后吸附速率减缓,在30 min左右基本达到吸附平衡. 这表明,在刚开始吸附阶段,吸附剂表面暴露的大量活性位点可以很迅速地捕获水中的磷酸盐. 随着时间的推移,吸附剂的表面吸附活性位点逐渐达到饱和,吸附过程随之减慢. 为深入了解PANAF-Cu对磷酸盐的吸附过程,分别通过拟一级动力学和拟二级动力学对吸附数据进行拟合. 拟合图和动力学参数分别如图5和表2所示,在288、298、308 K等3种温度下,拟二级动力学模型的R2均高于拟一级动力学模型;而且,用拟二级动力学模型拟合的qe值也更贴近于实际的吸附量. 因此,该吸附剂对磷酸盐的吸附过程更加倾向于化学吸附[25].
表 2 PANAF-Cu对磷酸盐的动力学参数Table 2. Kinetic parameters of PANAF-Cu on phosphateT/K 拟一级动力学模型Quasi-first-order kinetic model 拟二级动力学模型Quasi-second-order kinetic model K1/ min qe /(mg·g−1) R2 K2 /min−1 qe/ (mg·g−1) R2 288 0.824 19.781 0.754 0.056 21.533 0.952 298 0.999 20.700 0.688 0.066 22.237 0.931 308 0.927 21.754 0.627 0.073 23.379 0.906 | Show TableDownLoad:
CSV
2.3.3 吸附等温线分析
为了阐明PANAF-Cu对磷酸盐的吸附模式和吸附性能,在室温下,对不同初始磷酸盐浓度下进行了吸附等温实验. 实验发现,吸附剂对磷酸盐的吸附能力伴随着磷酸盐初始浓度的升高而增强,直至吸附饱和. 这可能是因为在较低的磷酸盐浓度下,磷的配位位点更多,随着磷浓度的提高,活性吸附位点也逐渐达到饱和,吸附量不再升高. 利用Langmuir和Freundlich吸附等温线模型对数据进行拟合,通过拟合得到的图和相关数据分别位于图6和表3.
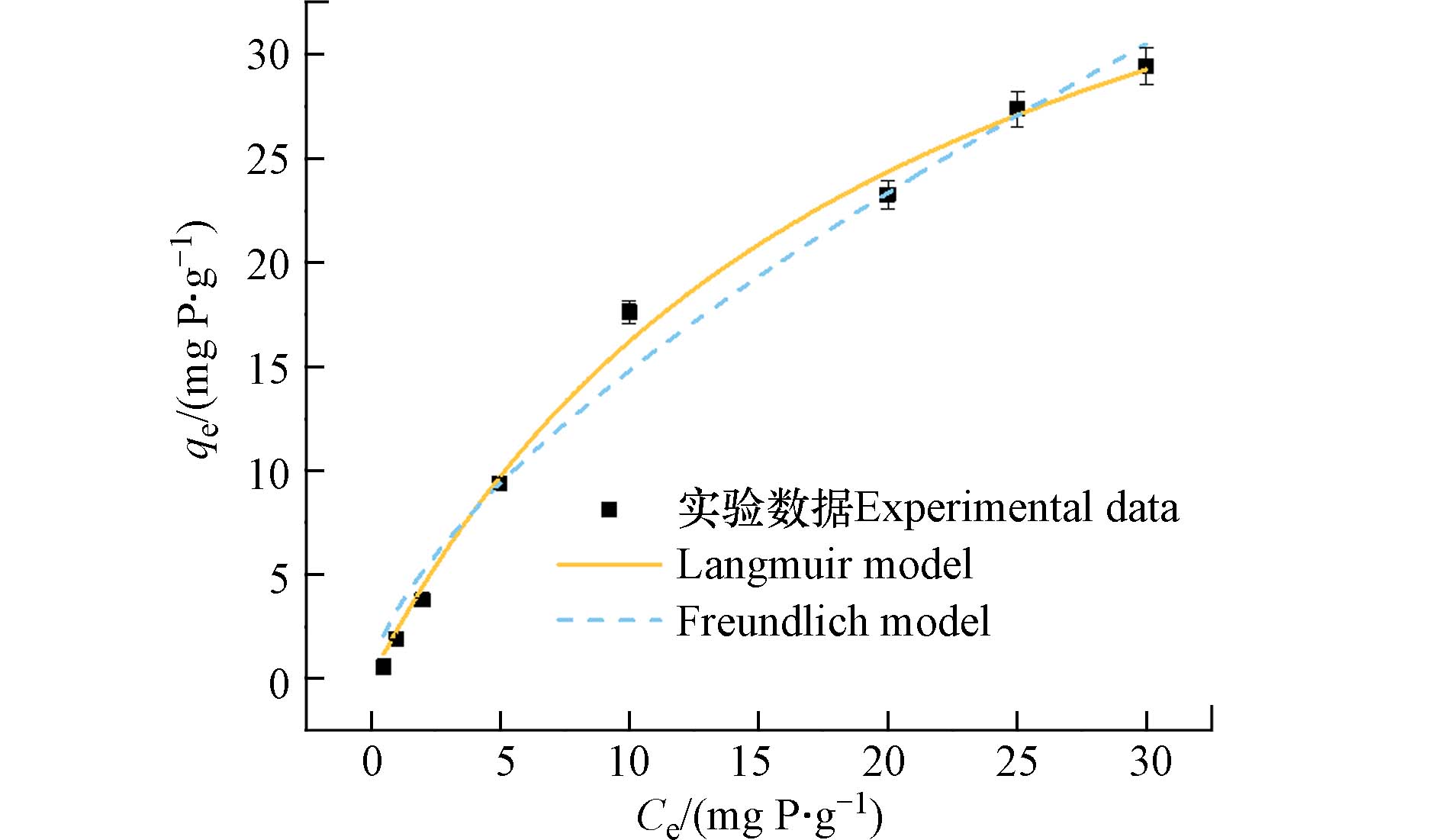 图 6 PANAF-Cu对磷酸盐的吸附等温线模型Figure 6. Isothermal model of phosphate adsorption by PANAF-Cu
图 6 PANAF-Cu对磷酸盐的吸附等温线模型Figure 6. Isothermal model of phosphate adsorption by PANAF-Cu从表3可以看出,Langmuir模型拟合曲线的回归参数大于Freundlich模型,说明PANAF-Cu对磷酸盐的吸附更适合于Langmuir模型. 因此,吸附剂对磷酸盐的吸附更趋向于均匀的单分子层化学吸附. 通过Langmuir模型估算PANAF-Cu对磷酸盐的最大吸附量为49.03 mg·g−1.
表 3 PANAF-Cu对磷酸盐的等温学参数Table 3. Isothermal parameters of PANAF-Cu on phosphateLangmuir Freundlich qe /(mg·g−1) KL/(L·mg−1) R2 KF /(mg·g−1·(L·mg−1)1/n) 1/n R2 49.026 20.258 0.995 3.242 0.659 0.982 | Show TableDownLoad:
CSV
2.3.4 共存阴离子影响
为测定PANAF-Cu对磷酸盐去除的选择性,选定硫酸盐、氯化物、硝酸盐和碳酸盐为代表性的共存阴离子. 在浓度为1×10−3 mol·L−1的磷酸盐中分别加入同等浓度的Cl−、NO3−、CO32-以及SO42-等共存离子溶液,探究PANAF-Cu对磷酸盐的吸附能力,结果见图7. 结果表明, 4种共存离子对PANAF-Cu吸附磷酸盐的影响如下:SO42-﹥CO32-﹥Cl−﹥NO3−. 其中NO3−对磷酸盐的吸附影响最小. SO42-和CO32-比Cl−和NO3−更有竞争力,可能是因为硫酸盐和碳酸盐作为二价离子具有更高的电荷密度,比单价阴离子能更迅速地被吸附. 以上实验说明PANAF-Cu在实际水体中也能在较多阴离子的影响下具有很好的除磷效果.
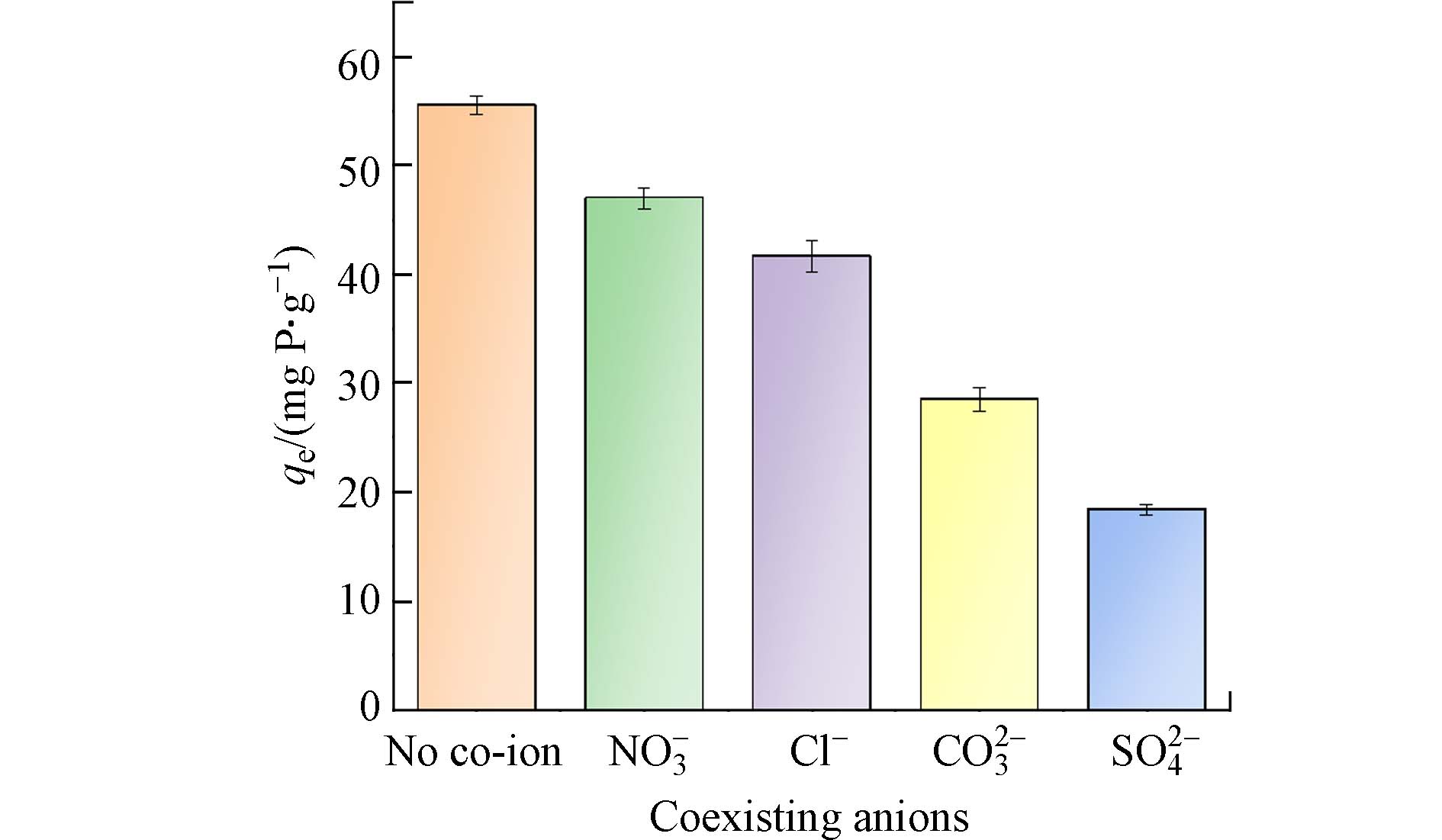 图 7 共存离子对PANAF-Cu吸附磷酸盐的影响Figure 7. Effect of coexisting ions on phosphate adsorption by PANAF-Cu
图 7 共存离子对PANAF-Cu吸附磷酸盐的影响Figure 7. Effect of coexisting ions on phosphate adsorption by PANAF-Cu2.3.5 吸附机理
XPS分析进一步揭示了吸附剂的化学状态和元素组成. 图8显示了吸附前后PANAF-Cu纤维的XPS光谱,与PANAF相比,PANAF-Cu出现了新的Cu元素的峰(图8a),这表明Cu2+成功的固载到了胺化纤维上,吸附后的纤维中出现了一个133.5 eV的信号峰,这是由P 2p轨道引起的,表明磷酸盐被纤维成功捕获(图8b). Cu2+对磷酸盐吸附的贡献由纤维吸附后Cu元素的高分辨率光谱证明(图8 c-d),对比吸附前的纤维,Cu的高分辨率光谱发现,PANAF-Cu-P的高分辨率Cu 2p光谱被分解成两个峰,最初位于934.73 eV的Cu—N键结合能下降到932.61 eV,这可以归因于来自磷酸盐的P原子为Cu提供了额外的电子,形成了新的N-Cu-P配位键,从而增加了Cu元素电子云密度,降低了结合能,这证实了改性纤维表面的Cu2+通过配位吸收起到了对P的固化作用. 即表明络合-配体相互作用是该吸附过程的主要机制[26]. 根据N的吸附前后的高分辨率光谱(图8 e-f)发现原本位于400.62 eV 的—NH2(—NH)键结合能下降到399.93 eV,氨基与Cu离子形成Cu-N的配位结构,纤维表面的Cu2+通过和磷酸盐中P—O键作用形成新的N-Cu-P配位去除磷酸盐,该基团的移动表明含氮官能团在PANAF-Cu对废水中的磷酸盐的吸附中起着重要作用. 因此根据上述结果,可以推断PANAF-Cu对磷酸盐的有效吸附主要依赖于纤维表面的Cu-N配位结构,从而形成新的N-Cu-P配位结构.
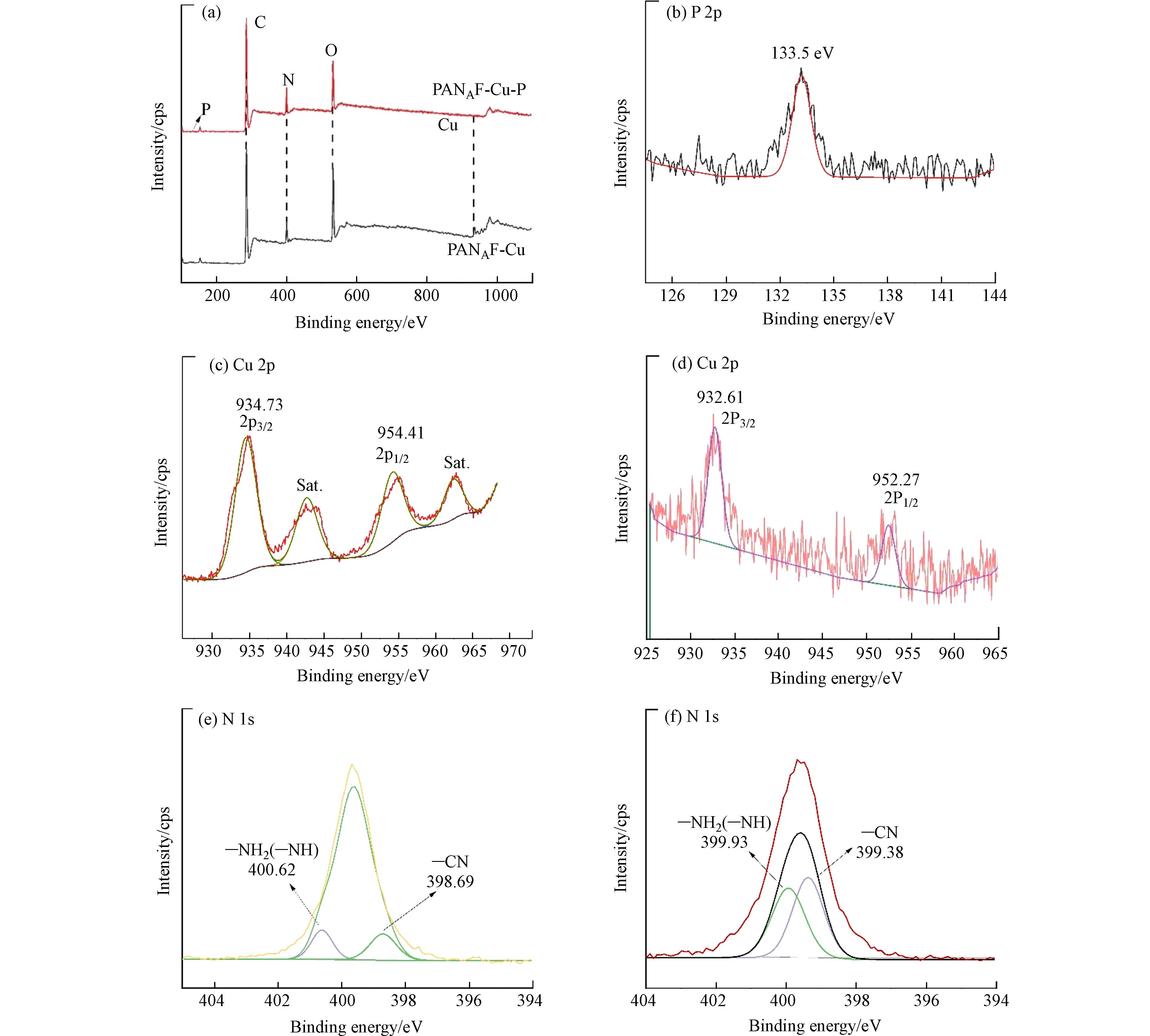 图 8 功能化纤维吸附磷酸盐前后的XPS谱图Figure 8. XPS spectra of functionalized fibers before and after phosphate adsorption(a)PANAF-Cu吸附磷酸盐前后的XPS总谱图,(b)P 2p的高分辨光谱图,(c-d)PANAF-Cu吸附磷酸盐前、后的Cu 2p的高分辨光谱图,(e-f)PANAF-Cu吸附磷酸盐前、后的N 1s的高分辨光谱图(a) XPS survey spectra of PANAF-Cu before and after phosphate adsorption, (b) High resolution XPS spectrum of P2p, (c-d) High resolution XPS spectrum of Cu2p before and after phosphate adsorption, (e-f) High resolution XPS spectrum of N1s before and after phosphate adsorption
图 8 功能化纤维吸附磷酸盐前后的XPS谱图Figure 8. XPS spectra of functionalized fibers before and after phosphate adsorption(a)PANAF-Cu吸附磷酸盐前后的XPS总谱图,(b)P 2p的高分辨光谱图,(c-d)PANAF-Cu吸附磷酸盐前、后的Cu 2p的高分辨光谱图,(e-f)PANAF-Cu吸附磷酸盐前、后的N 1s的高分辨光谱图(a) XPS survey spectra of PANAF-Cu before and after phosphate adsorption, (b) High resolution XPS spectrum of P2p, (c-d) High resolution XPS spectrum of Cu2p before and after phosphate adsorption, (e-f) High resolution XPS spectrum of N1s before and after phosphate adsorption2.3.6 循环性能实验
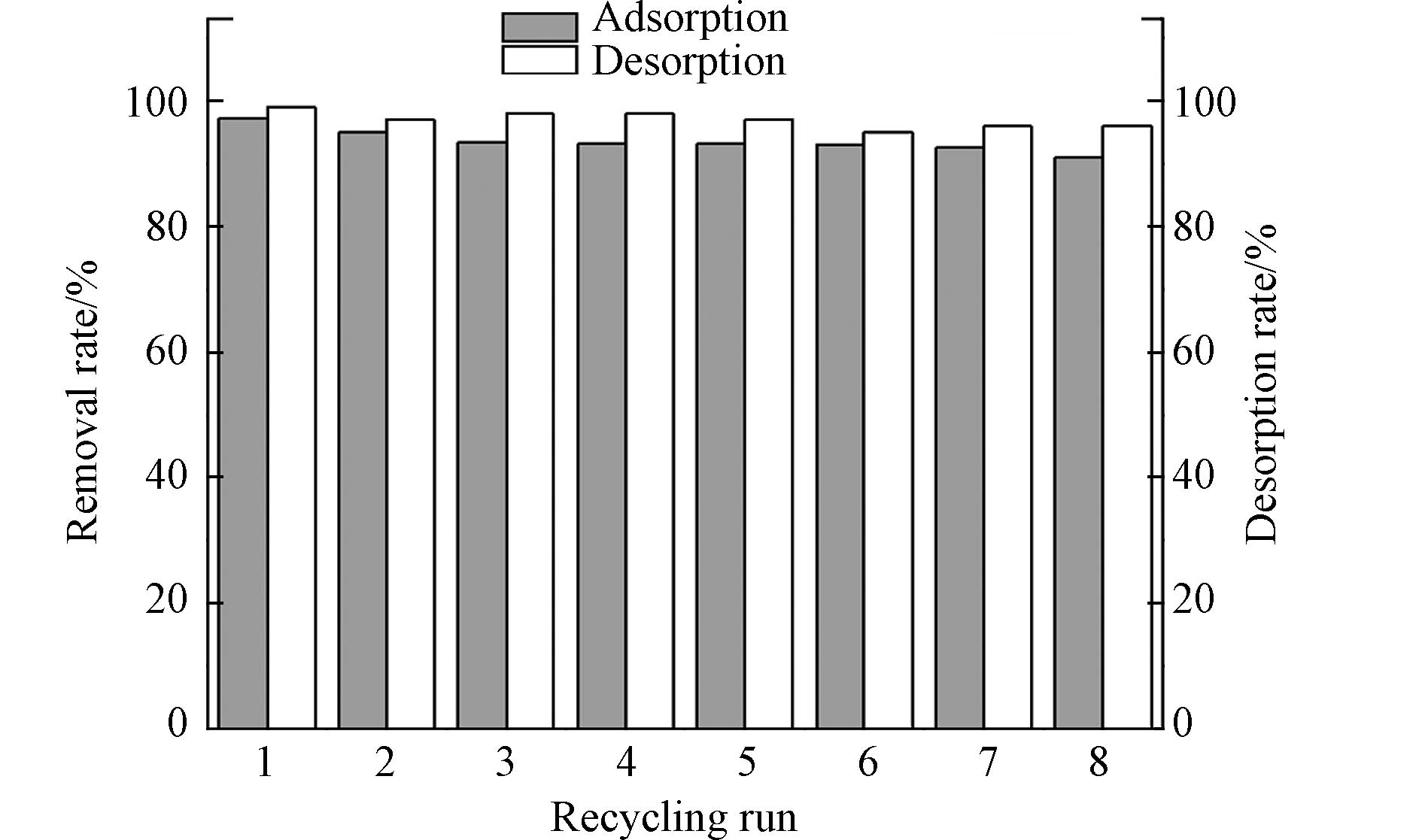
为探究不同解吸剂对磷酸盐的解吸率影响,进行对比实验(表4),发现HCl、NaCl、C6H8O7(柠檬酸)和EDTA(乙二胺四乙酸二钠)对磷酸盐的解吸率分别为52.50%、2.50%、87.50%和97.50%,EDTA的解吸率最高为97.5%. 从图9可以看出,经过8次循环后,PANAF-Cu对磷酸盐的解吸率基本稳定在90%以上,相应的解吸率也保持在95%以上,表明PANAF-Cu具有多重吸附和再生的优良特性.
表 4 不同洗脱液对PANAF-Cu吸附磷酸盐后的解吸率Table 4. Desorption rate of phosphate adsorbed by different eluents to PANAF-Cu洗脱剂Eluent 浓度/(mmol·L−1)Concentration V/mL T/ h 解吸率/%Desorption rate HCl 1 50 1 52.5 NaCl 1 50 1 2.5 C6H3O7 1 50 1 87.5 EDTA 1 50 1 97.5 | Show TableDownLoad:
CSV
2.3.7 改性纤维在连续流动实验中的应用
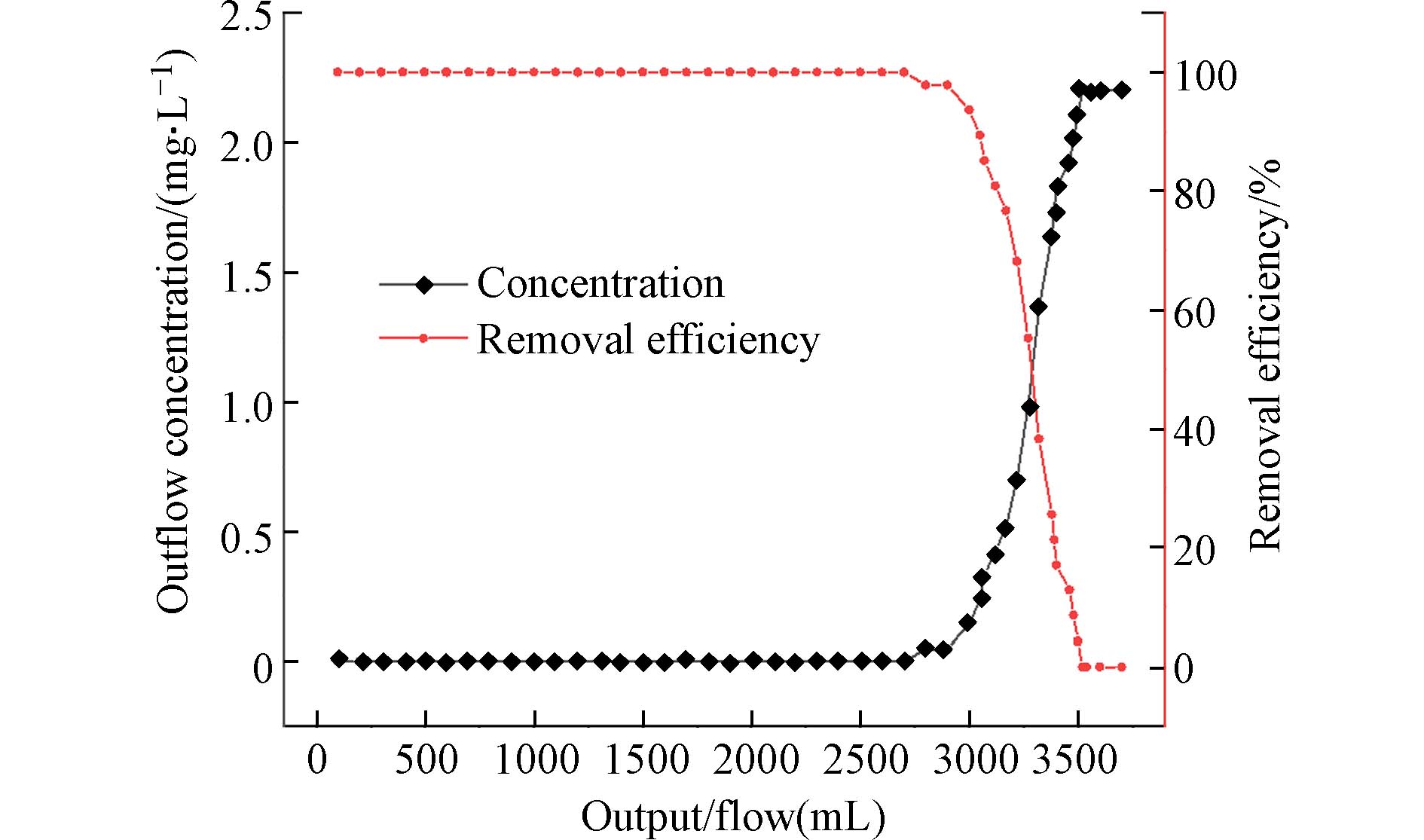
用初始浓度为2 mg·L−1的磷酸盐溶液利用恒流泵以0.5 mL·min−1的速率进行连续流动实验. 每隔50 mL测试出水中的磷酸盐浓度,就可以绘制出磷酸盐的穿透曲线,如图10所示. 实验发现,随着出水量的增加,出水中的磷酸盐浓度也随之增加. 当出水量小于2700 mL时,磷酸盐去除率维持在99%以上,大于2700 mL后,对硫酸盐的去除率大幅度下降. 这些结果皆说明PANAF-Cu在模拟自然水体和流动的水体条件下的具有优异除磷效果.
2.3.8 PANAF-Cu在实际废水中除磷性能研究
本研究进一步探究PANAF-Cu在实际水体的应用效果,测试了PANAF-Cu对巢湖(自然水体)磷污染水体中对磷的吸附能力. 为了更好地说明问题,将采集的水样的磷酸盐浓度调整为1000 µg· L−1 P. 分别将0、5、10、20、40、60 mg的PANAF-Cu置于10 mL上述水样中搅拌24h,利用ICP测定剩余磷酸盐浓度,测定结果见表5. 实验表明,当PANAF-Cu添加量超过20 mg时,磷酸盐浓度即可降至100 µg·L−1以下,已低于湖泊富营养化的最小磷浓度200 µg·L−1. 可见,本研究制备得到的少量PANAF-Cu在实际水体中也可以有效的降低水体的富营养化程度.
表 5 PANAF-Cu对磷酸盐的吸附极限测试Table 5. Adsorption limit test of phosphate by PANAF-CuPANAF-Cu的质量Quality of PANAF-Cu 体积/ mLVolume 时间/ hTime 磷酸盐浓度/(µg·L−1 P)Phosphate concentration 0 10 24 1113 5 10 24 759 10 10 24 393 20 10 24 98 40 10 24 92 60 10 24 90 | Show TableDownLoad:
CSV
2.3.9 与其他除磷吸附剂的比较
为了评估功能纤维吸附剂的吸附效果,表6列出了近年来报道的一些用于去除废水P的吸附剂材料. 值得注意的是,本工作中合成的铜胺负载纤维可以在较温和的反应条件下就可以获得较高的吸附能力. 此外,与表中列举的其他吸附剂有限的P吸附能力相比,接枝了Cu-N配体结构的功能化纤维表现出了更高的P容量和更快的吸附速率. 这可以归因于配位中心的铜离子和-NH2中的N原子之间的配位模式所引起的铜离子的高反应性以及形成的N-Cu-P之间的独特结合机制. 此外,PANAF-Cu在循环使用8次以后依然能够有效地去除磷酸盐. 总的来说,与目前报道的磷酸盐选择性吸附材料相比,本课题中报道的功能纤维吸附剂在常温下具有更高的反应活性和更好的选择性吸附性能.
表 6 与其他除磷吸附剂的比较Table 6. Comparison with other phosphorus removal adsorbent吸附剂Adsorbent 吸附时间Adsorption time 最大吸附量(mg·g−1)Maximum adsorption capacity 循环次数Number of cycles 参考文献 黏土-牡蛎壳复合吸附材料 7 d 10 — [27] 鸟蛤壳粉 20 min 7.1 — [28] 掺杂淀粉的磷石膏和磷矿浮选尾矿 60 min 31.28 — [29] 淀粉包裹的Fe3O4纳米颗粒 90 min 7.73 3 [30] 磁性淀粉基Fe3O4黏土聚合物(CIONP) 2 h 3.12 3 [31] 炼钢渣 72 h 10.21 — [32] 掺杂SiO2的活性炭 1 h 0.65 — [33] 固载Fe2+的活性炭 4 h 14.12 — [34] 固载铜离子的功能化腈纶纤维(PANAF-Cu) 24 h 26.99 8 本研究 | Show TableDownLoad:
CSV
3. 结论(Conclusion)
以聚丙烯腈纤维为原料,通过胺化改性使得聚丙烯腈纤维表面固载胺基,在通过胺基与铜的配位作用,成功合成具有Cu-N配位结构的新型吸附剂(PANAF-Cu). 在pH=7时达到吸附量最大值26.99 mg·g−1,pH值在5—8的条件下,吸附量仍能保持到10 mg·g−1以上. 表明固载铜离子的胺化改性纤维具有较高且稳定的磷酸盐去除效率. PANAF-Cu的吸附过程更符合伪二级动力学吸附模型,吸附等温学拟合结果更适合Langmuir等温模型,表明P在PANAF-Cu属单分子层吸附,在一定温度内,对磷酸盐的去除效果随着温度升高而增加. 通过吸/脱附循环性能试验,经过8次循环后,PANAF-Cu对磷酸盐的吸附率基本稳定在90%以上,相应的解吸度效率也保持在95%以上,PANAF-Cu良好的除磷可循环性;吸附极限试验表明当出水量达到2700 mL时,对磷酸盐的去除率仍达到99%,具有较高的实际应用能力. XPS解析表明,PANAF-Cu对磷酸盐的吸附机理主要为纤维表面形成新的N-Cu-P配位结. PANAF-Cu对治理磷污染的废水具有很大的应用优势,是一种高效净化与回收水体磷酸盐的吸附材料.
-
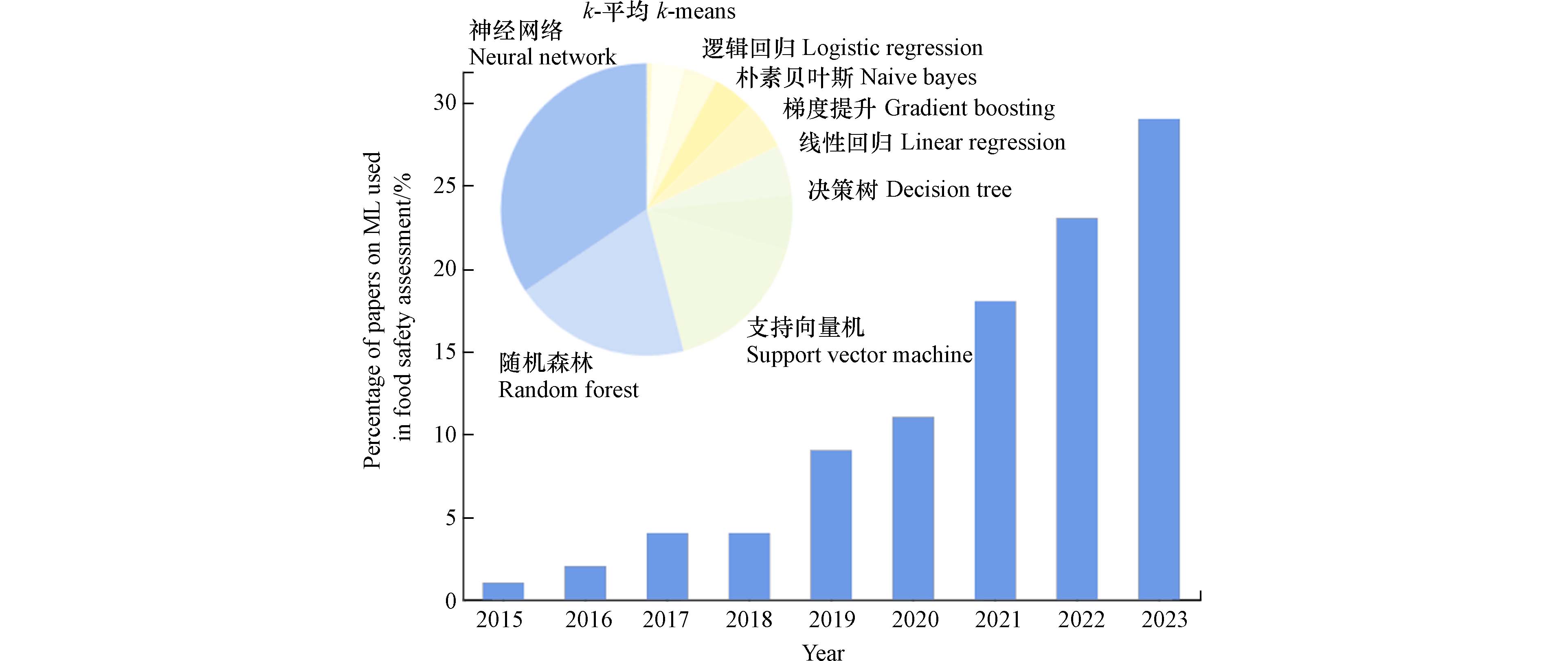
图 2 2015—023年基于机器学习的食品安全风险评估的相关文章
Figure 2. Related articles on machine learning-based food safety risk assessment, 2015—2023

图 3 QSAR及Read-Across的在风险评估中的应用特点
Figure 3. Application characteristics of QSAR and Read-Across in risk assessment
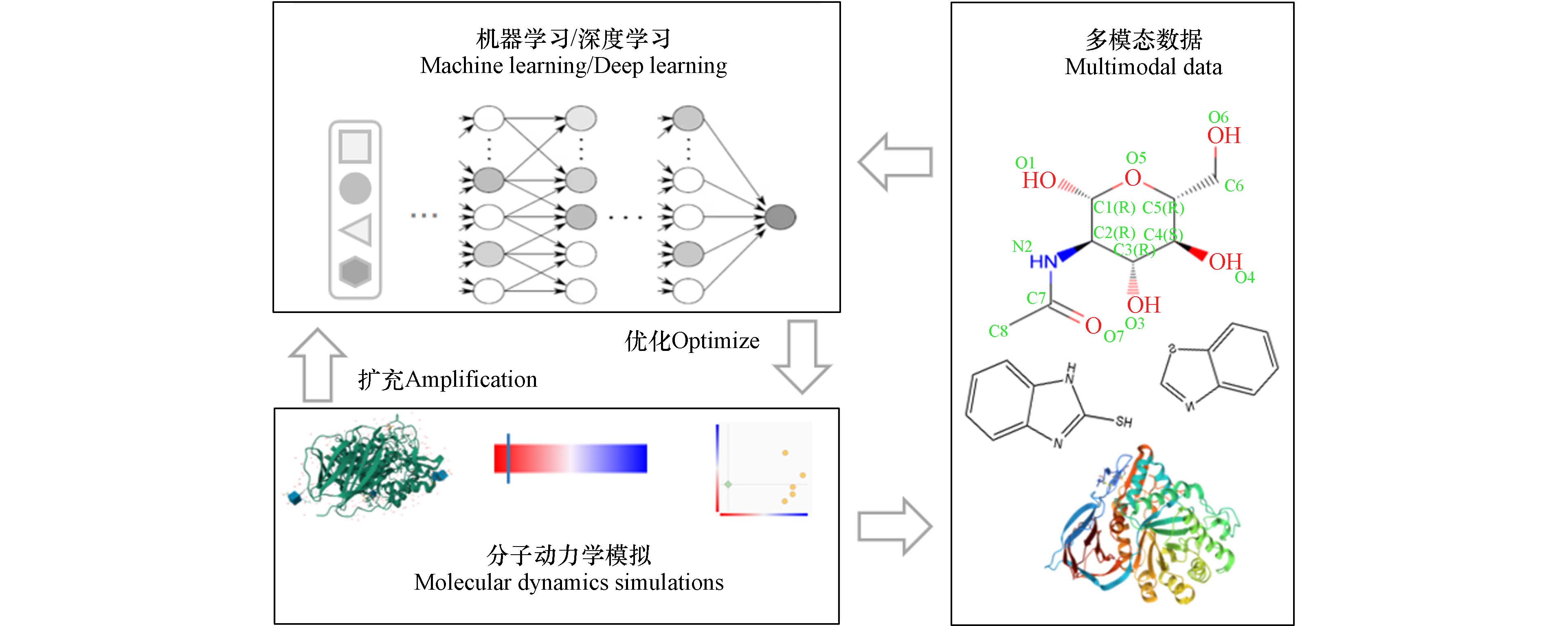
图 4 分子动力学模拟与机器学习联合应用
Figure 4. Joint application of molecular dynamics simulations and machine learning
-
[1] Toxicity testing in the 21st century: a vision and a strategy[M]. Washington, DC: National Academies Press, 2007. [2] YANG D Y, YANG H, SHI M Y, et al. Advancing food safety risk assessment in China: Development of new approach methodologies (NAMs)[J]. Frontiers in Toxicology, 2023, 5: 1292373. doi: 10.3389/ftox.2023.1292373 [3] Supporting Individual Risk Assessment during COVID-19[M]. Washington D C : National Academies Press, 2022. [4] HAN P L, LI X H, YANG J Y, et al. Advancing toxicity predictions: A review on in vitro to in vivo extrapolation in next-generation risk assessment[J]. Environment & Health, 2024, 2(7): 499-513. [5] HSCHMEISSER S,MICCOLI A,von BERGEN M,et al. New approach methodologies in human regulatory toxicology–Not if,but how and when![J]. Environment International, 2023(178): 108082. [6] DENG X Y, CAO S H, HORN A L. Emerging applications of machine learning in food safety[J]. Annual Review of Food Science and Technology, 2021, 12: 513-538. doi: 10.1146/annurev-food-071720-024112 [7] ALEXANDER-WHITE C, BURY D, CRONIN M, et al. A 10-step framework for use of read-across (RAX) in next generation risk assessment (NGRA) for cosmetics safety assessment[J]. Regulatory Toxicology and Pharmacology, 2022, 129: 105094. doi: 10.1016/j.yrtph.2021.105094 [8] LIM K, PAN K, YU Z, et al. Pattern recognition based on machine learning identifies oil adulteration and edible oil mixtures[J]. Nature Communications, 2020, 11(1): 5353. doi: 10.1038/s41467-020-19137-6 [9] BOUZEMBRAK Y, MARVIN H J P. Impact of drivers of change, including climatic factors, on the occurrence of chemical food safety hazards in fruits and vegetables: A Bayesian Network approach[J]. Food Control, 2019, 97: 67-76. doi: 10.1016/j.foodcont.2018.10.021 [10] ZHENG C, SONG Y H, MA Y P. Public opinion prediction model of food safety events network based on BP neural network[J]. IOP Conference Series: Materials Science and Engineering, 2020, 719(1): 012078. doi: 10.1088/1757-899X/719/1/012078 [11] ZHANG R F, ZHOU L, ZUO M, et al. Prediction of dairy product quality risk based on extreme learning machine[C]. 2018 2nd International Conference on Data Science and Business Analytics (ICDSBA), Changsha, China, 2018: 448-456. [12] MA Y, J HOU Y Y, LIU Y S, et al. Research of food safety risk assessment methods based on big data[C]. IEEE International Conference on Big Data Analysis (ICBDA), Hangzhou, China, 2016: 1-5. [13] CHANG W T, Yeh Y P, WU H Y, et al. An automated alarm system for food safety by using electronic invoices[J]. PLoS One, 2020, 15(1): e0228035. doi: 10.1371/journal.pone.0228035 [14] SCHILTER B, BENIGNI R, BOOBIS A, et al. Establishing the level of safety concern for chemicals in food without the need for toxicity testing[J]. Regulatory Toxicology and Pharmacology, 2014, 68(2): 275-296. doi: 10.1016/j.yrtph.2013.08.018 [15] LI X L, CHENG W, YANG S F, et al. Establishment of a 13 genes-based molecular prediction score model to discriminate the neurotoxic potential of food relevant-chemicals[J]. Toxicology Letters, 2022, 355: 1-18. doi: 10.1016/j.toxlet.2021.10.013 [16] LI T, TONG W D, ROBERTS R, et al. DeepCarc: Deep learning-powered carcinogenicity prediction using model-level representation[J]. Frontiers in Artificial Intelligence, 2021, 4: 757780. doi: 10.3389/frai.2021.757780 [17] RUIZ-SAAVEDRA S, GARCÍA-GONZÁLEZ H, ARBOLEYA S, et al. Intestinal microbiota alterations by dietary exposure to chemicals from food cooking and processing. Application of data science for risk prediction[J]. Computational and Structural Biotechnology Journal, 2021, 19: 1081-1091. doi: 10.1016/j.csbj.2021.01.037 [18] WANG C C, LIANG Y C, WANG S S, et al. A machine learning-driven approach for prioritizing food contact chemicals of carcinogenic concern based on complementary in silico methods[J]. Food and Chemical Toxicology, 2022, 160: 112802. doi: 10.1016/j.fct.2021.112802 [19] 佘僧, 李熠, 宋洪波, 等. 稳定同位素技术在蜂蜜真实性溯源中的研究进展[J]. 食品工业科技, 2018, 39(17): 300-304,308. SHE S, LI Y, SONG H B, et al. Research progress of stable isotope ratio mass spectrometry for authenticity and traceability in honey[J]. Science and Technology of Food Industry, 2018, 39(17): 300-304,308 (in Chinese).
[20] 杜晓宁, 张鹏帅, 雷雯, 等. 稳定同位素技术在我国食品安全检测领域的应用进展[J]. 同位素, 2019, 32(3): 231-243. doi: 10.7538/tws.2019.32.03.0231 DU X N, ZHANG P S, LEI W, et al. Application of stable isotope technique in food safety field[J]. Journal of Isotopes, 2019, 32(3): 231-243 (in Chinese). doi: 10.7538/tws.2019.32.03.0231
[21] ERDÉLYI D, KERN Z, NYITRAI T, et al. Predicting the spatial distribution of stable isotopes in precipitation using a machine learning approach: A comparative assessment of random forest variants[J]. GEM - International Journal on Geomathematics, 2023, 14(1): 14. doi: 10.1007/s13137-023-00224-x [22] 王中钰, 陈景文, 傅志强, 等. QSAR模型应用域的表征方法[J]. 科学通报, 2022, 67(3): 255-266. doi: 10.1360/TB-2021-0406 WANG Z Y, CHEN J W, FU Z Q, et al. Characterization of applicability domains for QSAR models[J]. Chinese Science Bulletin, 2022, 67(3): 255-266 (in Chinese). doi: 10.1360/TB-2021-0406
[23] TROPSHA A, ISAYEV O, VARNEK A, et al. Integrating QSAR modelling and deep learning in drug discovery: The emergence of deep QSAR[J]. Nature Reviews. Drug Discovery, 2024, 23(2): 141-155. doi: 10.1038/s41573-023-00832-0 [24] BHHATARAI B, WILSON D M, PRICE P S, et al. Evaluation of OASIS QSAR models using ToxCast™ in vitro estrogen and androgen receptor binding data and application in an integrated endocrine screening approach[J]. Environmental Health Perspectives, 2016, 124(9): 1453-1461. doi: 10.1289/EHP184 [25] RYU J Y, KIM H U, LEE S Y. Deep learning improves prediction of drug-drug and drug-food interactions[J]. Proceedings of the National Academy of Sciences of the United States of America, 2018, 115(18): E4304-E4311. [26] RUSSO D P, ZORN K M, CLARK A M, et al. Comparing multiple machine learning algorithms and metrics for estrogen receptor binding prediction[J]. Molecular Pharmaceutics, 2018, 15(10): 4361-4370. doi: 10.1021/acs.molpharmaceut.8b00546 [27] IDAKWO G, THANGAPANDIAN S, LUTTRELL J 4th, et al. Deep learning-based structure-activity relationship modeling for multi-category toxicity classification: A case study of 10K Tox21 chemicals with high-throughput cell-based androgen receptor bioassay data[J]. Frontiers in Physiology, 2019, 10: 1044. doi: 10.3389/fphys.2019.01044 [28] WANG H, LIU R F, SCHYMAN P, et al. Deep neural network models for predicting chemically induced liver toxicity endpoints from transcriptomic responses[J]. Frontiers in Pharmacology, 2019, 10: 42. doi: 10.3389/fphar.2019.00042 [29] FERNANDEZ M, BAN F Q, WOO G, et al. Toxic colors: The use of deep learning for predicting toxicity of compounds merely from their graphic images[J]. Journal of Chemical Information and Modeling, 2018, 58(8): 1533-1543. doi: 10.1021/acs.jcim.8b00338 [30] GOH G B, SIEGEL C, VISHNU A, et al. Chemception: A deep neural network with minimal chemistry knowledge matches the performance of expert-developed QSAR/QSPR models[EB/OL]. 2017: 1706.06689. [31] van LEEUWEN K, SCHULTZ T W, HENRY T, et al. Using chemical categories to fill data gaps in hazard assessment[J]. SAR and QSAR in Environmental Research, 2009, 20(3/4): 207-220. [32] CHATTERJEE M, ROY K. Chemical similarity and machine learning-based approaches for the prediction of aquatic toxicity of binary and multicomponent pharmaceutical and pesticide mixtures against Aliivibrio fischeri[J]. Chemosphere, 2022, 308: 136463. doi: 10.1016/j.chemosphere.2022.136463 [33] HARTUNG T. Making big sense from big data in toxicology by read-across[J]. ALTEX, 2016, 33(2): 83-93. [34] BANERJEE A, ROY K. Machine-learning-based similarity meets traditional QSAR: “q-RASAR” for the enhancement of the external predictivity and detection of prediction confidence outliers in an hERG toxicity dataset[J]. Chemometrics and Intelligent Laboratory Systems, 2023, 237: 104829. doi: 10.1016/j.chemolab.2023.104829 [35] YANG C, RATHMAN J F, MOSTRAG A, et al. High throughput read-across for screening a large inventory of related structures by balancing artificial intelligence/machine learning and human knowledge[J]. Chemical Research in Toxicology, 2023, 36(7): 1081-1106. doi: 10.1021/acs.chemrestox.3c00062 [36] 潘柳萌, 吕翾, 庄树林. 分子动力学模拟在有机污染物毒性作用机制中的应用[J]. 科学通报, 2015, 60(19): 1781-1788. doi: 10.1360/N972015-00118 PAN L M, LÜ X, ZHUANG S L. The application of molecular dynamics simulations in mechanism of toxicity of organic contaminants[J]. Chinese Science Bulletin, 2015, 60(19): 1781-1788 (in Chinese). doi: 10.1360/N972015-00118
[37] ZHANG Y J, LI S Y, MENG K, et al. Machine learning for sequence and structure-based protein-ligand interaction prediction[J]. Journal of Chemical Information and Modeling, 2024, 64(5): 1456-1472. doi: 10.1021/acs.jcim.3c01841 [38] LI Y Q, HSIEH C Y, LU R Q, et al. An adaptive graph learning method for automated molecular interactions and properties predictions[J]. Nature Machine Intelligence, 2022, 4: 645-651. doi: 10.1038/s42256-022-00501-8 [39] MASTROPIETRO A, PASCULLI G, BAJORATH J. Learning characteristics of graph neural networks predicting protein–ligand affinities[J]. Nature Machine Intelligence, 2023, 5: 1427-1436. doi: 10.1038/s42256-023-00756-9 [40] 张家晨, 张良, 庄树林. 分子起始事件在计算毒理学中的研究展望[J]. 环境化学, 2021, 40(9): 2629-2632. doi: 10.7524/j.issn.0254-6108.2021032602 ZHANG J C, ZHANG L, ZHUANG S L. Perspective of molecular initiating events in computational toxicology[J]. Environmental Chemistry, 2021, 40(9): 2629-2632 (in Chinese). doi: 10.7524/j.issn.0254-6108.2021032602
[41] 谭皓月, 张荣, 陈钦畅, 等. 基于计算毒理的环境污染物-生物大分子的相互作用研究[J]. 科学通报, 2022, 67(35): 4180-4191. doi: 10.1360/TB-2022-0613 TAN H Y, ZHANG R, CHEN Q C, et al. Computational toxicology studies on the interactions between environmental contaminants and biomacromolecules[J]. Chinese Science Bulletin, 2022, 67(35): 4180-4191 (in Chinese). doi: 10.1360/TB-2022-0613
[42] PANEL ON CONTAMINANTS IN THE FOOD CHAIN (EFSA CONTAM PANEL) E F S A, SCHRENK D, BIGNAMI M, et al. Risk to human health related to the presence of perfluoroalkyl substances in food[J]. EFSA Journal. European Food Safety Authority, 2020, 18(9): e06223. [43] SHARMA R, KAMBLE S S, GUNASEKARAN A, et al. A systematic literature review on machine learning applications for sustainable agriculture supply chain performance[J]. Computers & Operations Research, 2020, 119: 104926. [44] PANSARI A, FAISAL M, JAMEI M, et al. Prediction of basic drug exposure in milk using a lactation model algorithm integrated within a physiologically based pharmacokinetic model[J]. Biopharmaceutics & Drug Disposition, 2022, 43(5): 201-212. [45] TAO T P, MASCHMEYER I, LeCLUYSE E L, et al. Development of a microphysiological skin-liver-thyroid Chip3 model and its application to evaluate the effects on thyroid hormones of topically applied cosmetic ingredients under consumer-relevant conditions[J]. Frontiers in Pharmacology, 2023, 14: 1076254. doi: 10.3389/fphar.2023.1076254 [46] McNALLY K, LOIZOU G. Refinement and calibration of a human PBPK model for the plasticiser, Di-(2-propylheptyl) phthalate (DPHP) using in silico, in vitro and human biomonitoring data[J]. Frontiers in Pharmacology, 2023, 14: 1111433. doi: 10.3389/fphar.2023.1111433 [47] NAJJAR A, PUNT A, WAMBAUGH J, et al. Towards best use and regulatory acceptance of generic physiologically based kinetic (PBK) models for in vitro-to-in vivo extrapolation (IVIVE) in chemical risk assessment[J]. Archives of Toxicology, 2022, 96(12): 3407-3419. doi: 10.1007/s00204-022-03356-5 [48] MYUNG Y, de SÁ A G C, ASCHER D B. Deep-PK: Deep learning for small molecule pharmacokinetic and toxicity prediction[J]. Nucleic Acids Research, 2024, 52(W1): W469-W475. doi: 10.1093/nar/gkae254 [49] ZHANG S Y, WANG Z Y, CHEN J W, et al. Multimodal model to predict tissue-to-blood partition coefficients of chemicals in mammals and fish[J]. Environmental Science & Technology, 2024, 58(4): 1944-1953. [50] ALGHARABLY E A, Di CONSIGLIO E, TESTAI E, et al. Prediction of in vivo prenatal chlorpyrifos exposure leading to developmental neurotoxicity in humans based on in vitro toxicity data by quantitative in vitro-in vivo extrapolation[J]. Frontiers in Pharmacology, 2023, 14: 1136174. doi: 10.3389/fphar.2023.1136174 期刊类型引用(1)
1. 高燕. 胶黏剂产品中VOCs含量与类别的检测方法. 塑料助剂. 2024(03): 38-42 .  百度学术
百度学术
其他类型引用(0)
-
 点击查看大图
点击查看大图
计量
- 文章访问数: 1179
- HTML全文浏览数: 1179
- PDF下载数: 47
- 施引文献: 1
