





-
工业园区大气污染排放总量核算为园区大气环境质量管控提供重要依据,同时有助于推进企业排污许可、项目审批、执法监管以及排污权交易等管理联动,与排污总量挂钩,有助于提升综合管理效能、制定相关的环境管理政策[1]和解决污染源管控不准、产业调整方向不明、环评审批总量落实难、第三方机构弄虚作假等问题具有重要意义[2-3]。目前,工业园区大气污染物排放总量的核算主要是统计园区内所有企业大气污染物排放量并进行加和代表该园区大气污染物的排放总量。现有对企业排放量核算方法主要有实测法、产排污系数法及物料衡算法。实测法是依据实际监测环统对象产生和外排废气流量及其污染物质量浓度,计算出废气的排放量及各种污染物的产生量和排放量 (在线监测和手工监测) [4]。产排污系数法是根据《产排污系数手册》[5]提供的工业行业产排污系数,只要根据企业的实际情况选择合适的产排污系数,即可核算出污染物的产生量和排放量[6]。物料衡算法是通过计算生产过程中物质的量的变化对生产过程中使用的物料变化情况进行定量分析的一种方法[7]。但上述通过对企业排放量核算园区总排放量的方法均存在一定的局限性,如实测法 (在线监测和手工监测) 存在设备安装联网成本较高,运维困难、无法测算无组织排放等问题且监控数据无法验证[8-9]。产排污系数法忽视了企业生产过程中采取不同污染处理技术的因素,在计算过程中仅以企业生产消耗的原材料或生产成品就确定了一个企业的排放系数,未考虑企业对于污染管理和处理技术方面的因素,具有一定的局限性[6]。产排污系数法对于关键系数的选取存在一定主观性且可能会忽略行业特征[5]。而物料衡算法计算过程复杂,生产过程中的物料损耗、污染物的无组织排放等因素无法准确估算,适用范围较小等[4,10]。与此同时,产排污系数法和物料衡算法通常需要对生产企业进行调研,对于企业数量和类型较多的工业园区,核算的人力成本和时间成本较高,难以实现动态核算更新。
本研究尝试探索基于环境监测站点的实时监测数据,结合大气污染物扩散模型和源参数反演算法,构建工业园区大气污染物实际排放总量反演算法,实现对园区无组织及低矮有组织大气污染物实际排放量的动态实时核算。该方法可极大地节省人力、物力,具有普遍适用性。该方法可作为实测法、物料衡算法及产排污系数法等传统排放总量核算方法的有益补充,同时有助于充分利用环境监测数据信息,明确环境质量与污染物排放的动态响应关系,为基于环境质量目标的动态污染排放管控提供参考。
-
示例园区为东南沿海某重点石油化工产业基地,是国家石化产业布局方案中重点规划布局的新建石化产业基地。2021年,依据江苏省开展工业园区 (集中区) 污染物排放限值限量管理工作方案要求[2],建设了园区大气环境监测站点网络,并对园区企业大气污染排放情况进行了调查核算。该园区内共有涉及有机化学品的合成、储运、化学加工制造、危废治理、热电联产等污染排放企业20家。其生产及排放规模排名前10的企业VOCs排放总量占园区VOCs总排放量超过95%。因此,选取该10家企业作为主要研究对象,以VOCs的实际排放量实时反演为主要研究目标。由于本研究主要论证基于大气环境监测数据的污染排放总量实时反演的技术可行性,并讨论相关影响因素,故不考虑在工业园区尺度范围内VOCs的二次转化。
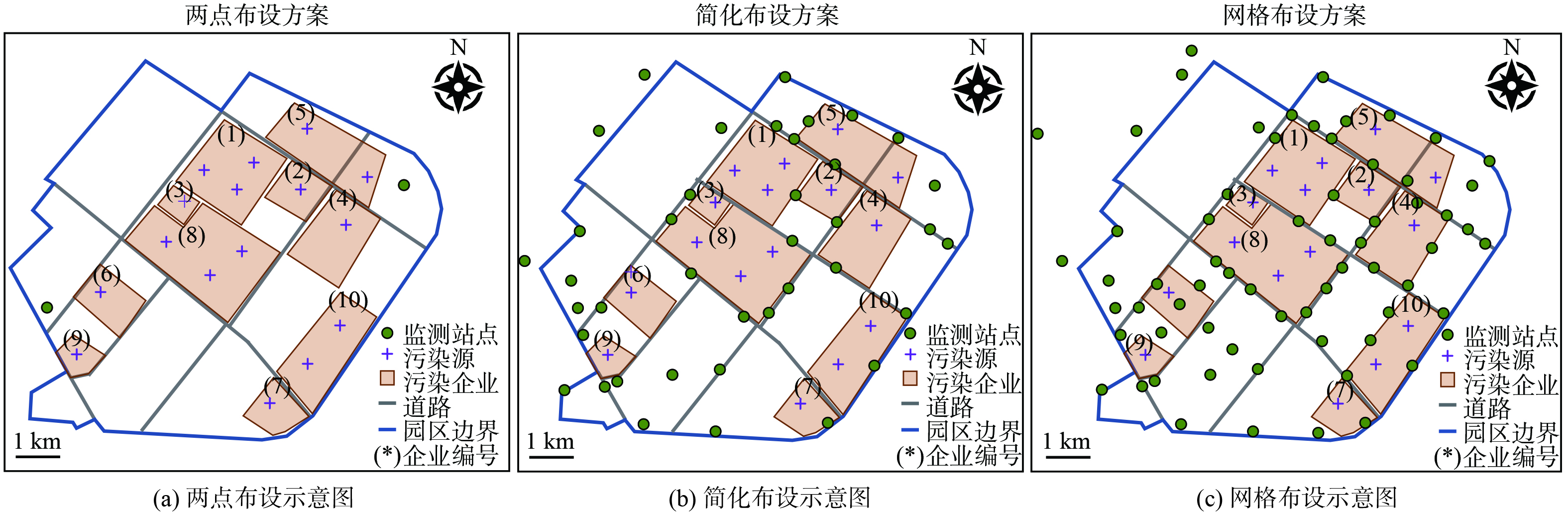
将园区在WGS-84地理坐标系下的企业排污单元及监测站点经纬度、园区边界及主要道路矢量图信息转化为UTM投影坐标系以方便进行数值模拟。图1为园区主要污染企业、监测站点、园区边界及主要道路的空间分布情况。
选取园区几何中心作为原点,计算各排污单元及监测站点的相对空间位置。表1为污染排放占比前10企业各污染排放点位的相对位置、排污许可中VOCs的年排放量 (许可排放量) ,以及通过在线监测、产能折算、产排污系数、物料衡算等方式核算的VOCs年排放量 (统计核算量) 。核算年度为2020年,部分企业如企业 (8) 、企业 (10) 在核算年度尚未正式投产,故其统计核算量处于缺失状态。在本研究过程中,相关企业已正式投产,故在模型模拟中将参考许可排放量作为污染源,考虑其排放过程对周边环境的影响。经统计,示例园区VOCs年排污许可量约为4 000 t。
-
本研究基于工业园区地面监测站点实时监测数据开展大气扩散模拟。其中,模型采用的平均风场数据为园区内各监测站点小时平均风向的平均值,计算式见式 (1) 和式 (2) 。
式中:
u 、v 分别为风向在纬线方向和经线方向的分量;ws 是风速,m∙s−1;θ 为以北风为0o的风向角度。式中:
um 、vm 分别为平均风向量在纬线方向和经线方向的分量;N 为监测站点总数;ui 、vi 分别为监测站点i的小时监测分量。 -
高斯烟羽大气污染扩散模型是基于随机扩散形成高斯分布的污染物浓度场理想假设的第一代空气质量模型,适用于平坦地形下稳态风向中污染物的扩散模拟。随着研究的深入,进一步推出了第二代空气质量模式如AERMOD[11]、CALPUFF[12]和第三代空气质量模式如CMAQ[13],考虑了更为复杂的影响大气污染物扩散及二次转化的因素。然而,由于其快速简单的特点,高斯模型仍在应急处置、污染初步估算等领域被广泛应用[14]。本研究主要讨论基于环境监测站点监测数据开展工业园区大气污染排放总量实时反演的技术可行性,为简化起见,采用高斯烟羽大气污染扩散模型对该方案进行测试。在实际使用中,其他空气质量模型也可类似地应用于工业园区总量核算中。
高斯烟羽大气污染扩散模型的解析形式见式 (3) 。
式中:
Q0 为污染源的排放强度,mg∙s−1;U 为平均风速,m∙s−1;σy 、σz 分别为横向和纵向的扩散参数,该参数的值是x 的函数,m;C(x,y,z) 为质量浓度关于三维空间位置的分布函数,mg∙m−3;y0 、z0 分别为污染源的空间位置。此处,x 是横向垂直于平均风向的方向,y是横向平行于平均风向的方向,z是纵向垂直于风场平面的方向。定义
α 为污染源对任意点位的污染物浓度贡献比率计算式为式 (4) ,则排放强度为Q0 的污染源对任意点位的污染浓度贡献可由Q0⋅α 得到,σy 、σz 的计算是高斯烟羽扩散模型应用的关键。本研究参考国标参数化方案《制定地方大气污染物排放标准的技术方法》 (GB/T 3840-91) [15]逐小时实时计算
σy 、σz 的数值。具体见式 (5) 。式中:参数
γ1 、γ2 和α1 、α2 具体取值与大气稳定度等级有关,大气稳定度等级可根据太阳倾角、云量、风速等气象信息估算获得。具体估算方法及参数取值参照标准GB/T 3840-91[5]。 -
监测站点污染物的监测质量浓度为背景质量浓度、污染源贡献质量浓度和监测误差累加而成。假设园区存在监测站点N个,污染源M个,则对于任意监测站点i,有监测污染物质量浓度
di 为式 (6) 。式中:
bg 为背景浓度。假设在工业园区尺度范围内,污染物的背景质量浓度是均一的常数,εi 为监测站点i对目标污染物的监测误差,其计算式为式 (7) 。式中:
ε 为控制监测误差强度的系数,χ 为均值为0,方差为1的高斯分布。以此构造优化目标函数见式 (8) 。
式中:
^bg 、ˆQj 分别为背景浓度和污染源j排放强度的估算值。该值将在优化目标函数的迭代过程中被不断优化,直到趋近于实际情况。a 、b 为目标函数的一阶和二阶正则项系数,该系数取值可通过贝叶斯优化获得。基于前人研究,对源参数反演的优化算法选取有较多讨论,如采用Nelder-Mead优化法[16]、粒子群算法 (PSO) [17]、遗传算法 (GA) [18-19]等。为验证基于环境监测站点开展工业园区大气污染物实际排放总量实时核算的可行性,本文采用基础的Nelder-Mead算法作为优化器。在实际使用中,可根据实际情况采用其他优化算法。 -
本研究主要采用平均绝对相对偏差 (Mean Absolute Relative Error, MARE) 作为排放总量反演误差的度量,其计算公式见式 (9) 。
式中:T为核算时段的小时数;
ˆxn ,xn 分别为反演排放量和模拟排放量;|⋅| 表示绝对值。 -
收集园区2023年1月1日0时至1月31日23时地面气象监测数据开展模拟研究。参考表1中收集的企业许可排放量数据设定模拟的污染源排放强度。其中,大型企业生产单元占地面积较大,存在多个排放点位 (如企业1) ,则将企业的年排放量均匀分配到每个排放点位。将各个点位的排放强度由t∙a−1转化为mg∙s−1带入公式 (3) 中,获取各污染源对监测点位贡献C,背景浓度设定为0~0.3 mg∙m−3的随机数。依照公式 (5) 可获得园区监测点位的监测浓度值
di 。为验证基于环境监测数据对工业园区排放总量进行实时反演核算的有效性和适用性,研究设定了4个不同排放情景:高排放情景、中排放情景、低排放情景和周期排放情景。其中,高、中、低排放情景分别为实际排放量占许可排放量的100%、50%和10%,周期排放情景则设定园区排放以24 h为周期依照正弦函数在许可排放量的20%~120%内波动。图2展示了高排放情境下,园区2023年1月1日00时污染物质量浓度及污染源对监测点位贡献比率的空间分布情况。
利用模拟的在线监测浓度值,以公式 (7) 为目标函数 (设定正则项为0) ,进行反演核算。图3展示了4种排放情景下逐小时的模拟排放量和反演排放量。结果表明,在该条件下模拟排放量逐小时变化曲线与模拟排放量的逐小时变化曲线基本一致,部分时刻存在明显偏差。
计算1月份逐小时反演排放总量与模拟排放总量的平均绝对相对偏差发现,在该条件下,模型反演背景浓度与模拟的实际背景浓度一致,其偏差极小,小时排放量反演偏差约为5.4%左右,且不同情境下偏差大小基本不变。这表明此时对园区的排放总量反演核算具有较好的效果。
同时,观察到图3中不同时刻的反演偏差有所差异,部分时段的反演偏差明显偏大。从反演机理考虑,该反演过程本质上是利用环境质量监测站点对污染源排放形成的扩散烟羽进行空间采样,再利用采样结果根据污染扩散公式对源排放参数进行约束优化,最终依靠目标函数优化寻找最符合采样结果的源排放参数。因此,采样过程的充分与否将直接影响反演效果。对于固定的污染源和监测点位分布,受气象条件影响的污染扩散烟羽的形态可能对采样造成影响。
为验证该猜想,对不同大气稳定度下的反演差异进行了统计分析(表2) 。结果表明,核算时段内大气稳定度等级主要集中于B、D、E、F这4种情况,总体呈现从A到F (强不稳定到稳定) ,反演偏差逐步增大的规律 (表3) 。参照标准GB/T 3840-91[15],反演效果较差的大气稳定度等级E、F主要出现于风速小于3.0 m∙s−1、太阳辐照等级较低的气象条件下。这一条件可能不利于污染物的扩散与传输,污染物空间分布较为集中,不利于监测点位对污染物扩散特征的监测采样,进而导致基于监测数据的反演效果较差。
利用风玫瑰图分析反演效果与风向的关系,分析发现反演绝对相对误差 (ARE) 较高的时刻,风向主要分布在西北-东南方向 (图4) 。这一风向与园区主导风向正交。该方向上的反演效果较差可能与该方向监测站点布点相对稀疏有关。
-
为进一步研究监测点位对反演效果的影响,对比了3种布点方案下的反演精度。两点布设指在园区主导风向的上下风向各布设一个监测点位;网格布设指在园区内及园区边界,依照1~2 km的距离网格式布设监测点位;简化布设则指介于两点布设与网格布设之间的一种情形,对应部分网格布设监测点位失效情形下的反演效果。前文的数据模拟实验是在简化布设条件下进行的。各布点方案的站点位置分布示意见图5。
不同布点方案对反演精度有显著影响(表4)。其中,两点布设方案在4种排放情境下偏差最大,基本无法对园区实际排放量进行有效评估。简化布设方案和网格化布设方案偏差均在可接受范围内。网格化布设方案偏差相比简化布设降低90%以上。因此,网格化布设方案能显著提高园区排放总量核算的精准度。这一结论进一步验证了前述采样充分程度显著影响反演精度的假设。从两点布设、简化布设到网格布设,监测站点的数量增多,对扩散烟羽的采样更加充分,对源排放参数的反演提供了更精确的约束,进而提升了反演的准确度。
-
在实际应用中,由于系统误差、随机误差的存在,导致监测站点对污染扩散烟羽的采样可能存在不确定性。对于经过定期校验及规范运维的监测站点,可考虑随机误差为采样误差的主要来源,故本文讨论随机误差对反演精度的影响。依照公式 (5) 模拟不同排放情境下反演精度与随机误差强度的关系。结果表明,公式 (7) 中的正则项显著提高了反演模型在监测数据存在误差时的精度。当不考虑监测误差时,公式 (7) 中的正则项可设置为0 (即不考虑正则化损失函数) ,但当监测数据叠加随机误差时,不考虑正则项将导致反演结果显著偏离模拟实际排放量。以下分析的反演精确度均为通过贝叶斯优化迭代50次后取最佳一阶和二阶正则化系数获得的反演精度。对于本研究的示例园区,正则化因子取值为10−4到10−20之间。
实验表明,在考虑随机误差的情况下,4种排放情景的反演精度存在一定的差异 (这与不考虑随机误差的情况不同) 。反演精度随排放量的增加而提高,低排放情景下反演偏差最大。周期排放情境下的反演偏差则与中排放情景接近。对于低排放情景,随机误差的标准差达到0.01 mg∙m−3时,小时反演偏差达到了30%;对于中、高排放情景及周期排放情景,随机误差标准差达到0.1 mg∙m−3时,小时反演偏差约为30% (图6) 。即在简化布点方案下,可接受反演误差范围内可忍受的随机误差强度约为0.01~0.1 mg∙m−3。以该园区的主要VOCs污染物丙烷为例,在25 ℃常温下,该误差强度相当于5.6~55.6 ppb。该数值大于《环境空气挥发性有机物气象色谱连续监测系统技术要求及检测方法》 (HJ1010-2018) [20]规定的监测误差,但小于或相当于《挥发性有机化合物光离子化检测仪校准规范》 (JJF 1172-2007) [21]规定的空气微站测量TVOC的误差。这表明采用空气微站监测数据可能会增大对工业园区的VOCs排放总量反演核算偏差。
-
1) 以东南沿海某石化园区为例,讨论了基于环境监测数据开展工业园区大气污染物实际排放量实时反演核算的技术可行性。该技术可实时动态测算工业园区低矮有组织排放及无组织排放总量的能力,可作为在线监测法、产排污系数法等传统排放总量核算方法的有效补充,提升工业园区基于环境质量开展污染排放动态管控的能力。
2) 基于高斯大气扩散模型及Nelder-Mead优化反演算法,测试并讨论了反演核算方法的准确度及其影响因素。监测站点布设方案显著影响反演核算精度,网格化布点方案有效提高了反演核算精度。监测数据的随机误差显著影响反演核算精度,在简化布点方案下,园区监测站点对VOCs的浓度监测误差应控制在0.1 mg∙m−3以下。园区总排放强度对反演核算精度存在一定影响,总排放量大的园区反演核算精度较高。反演核算精度与实时气象条件有关,当气象条件不适宜模型模拟污染物扩散或不适宜监测站点对污染物分布进行有效采样时,可能造成反演精度的下降。
3) 在工业园区开展基于环境监测数据的大气污染物排放总量核算研究具有可行性。同时,监测站点对污染源排放扩散烟羽的采样充分程度是影响反演精度的重要因素。因此,需要在监测站点布设方案比选、监测站点数据质量控制等方面进行精细化管理,以达到最优反演核算效果。
基于大气环境监测数据的工业园区污染物排放总量实时反演核算方法
Real-time estimation of atmospheric pollutant emission in industrial park with environment monitoring data
-
摘要: 工业园区既是重要的社会经济发展单元,也是主要的大气污染排放单元。综合利用环境监测数据和数值模拟方法,开展工业园区污染排放的动态精准管控,有助于提升工业园区大气环境管控效果,统筹园区经济发展与环境优化。以某工业园区为例,探索了基于环境监测数据,利用高斯大气扩散模型和源参数反演技术,实现小时级别的园区大气污染物排放总量反演核算的技术可行性。结果表明:1) 监测站点布设方案显著影响反演核算精度,网格化布点方案有效提高了反演核算精度;2) 监测数据的随机误差显著影响反演核算精度,在简化布点方案下,园区监测站点对VOCs质量浓度监测误差应控制在0.1 mg∙m−3以下;3) 园区总排放强度对反演核算精度存在一定影响,总排放量大的园区反演核算精度较高;4) 反演核算精度与实时气象条件有关,当气象条件不适宜模型模拟污染物扩散或不适宜监测站点对污染物分布进行有效采样时,可能造成反演精度的下降。以上结果表明,在工业园区开展基于环境监测数据的大气污染物排放总量核算研究具有可行性,但需要在监测站点布设方案比选、监测站点数据质量控制等方面进行精细化管理,以达到最优反演核算效果。Abstract: The industrial park is not only important for economic growth but also a major unit of atmospheric pollutant emission. Precise management of the atmospheric pollutant emission in real-time by utilizing the environment monitoring data and numerical simulation models may promote the capability of controlling air quality of industrial park. This work, taking an industrial park as an example, explores the possibility of hourly inversing the amount of pollutant emission with the air station monitor data as well as the gaussian dispersion model. The numerical experiments indicated several results: 1) The monitor-station layout planning affected the accuracy of the estimation significantly, grid-layout planning increased the estimation accuracy dramatically. 2) The random detection errors of the monitor-stations influenced the estimation accuracy, with simplify-grid planning, the random detection errors should be controlled below 0.1 mg∙m−3. 3) The total emission intensity of the industrial park influenced the overall accuracy, high intensity led to high relative accuracy. 4) The estimation accuracy can be affected by the real-time meteorological environment. When meteorological conditions are not suitable for pollutant diffusion it may cause a decrease in inversion accuracy due to the low efficiency in the pollutant distribution sampling by the air monitors. Based on the conclusions above, this study supports the feasibility of estimation the amount of air pollutant emission in real-time based on the air monitor data. But several aspects such as the station layout planning, data quality assurance should be carefully designed and controlled to get optimized accuracy.
-
Key words:
- industrial park /
- atmospheric pollutant emission /
- inversion estimation
-
我国大部分油田已进入高含水开采期。油田在生产开发过程中产生大量的采出水,而热采工艺需要消耗大量的蒸汽,蒸汽的水源主要是自来水,导致采出水处理量和回注量逐年增加[1],同时也消耗了大量的淡水资源。为了解决这一难题,近年来对采出水资源化进行了较多的研究[2]。
资源化利用的关键是解决采出水中含油量、悬浮物、矿化度、硬度过高的问题[3]。目前,较为成熟的技术是MVR[4-5]和反渗透工艺。MVR工艺的优点是产水率高,适用于高矿化度水质,但由于其成本较高、核心技术不易掌握,限制了推广范围,而反渗透工艺在一定程度上克服了这些缺点。反渗透膜不仅能有效去除有机物、降低COD,而且具有优异的脱盐效果[6]。采出水进行反渗透处理前通常需要利用超滤工艺进行预处理,超滤的主要作用是为了去除水中的悬浮物和细菌,以达到保护反渗透膜的目的。超滤工艺之前也需要进行预处理,主要是为了减轻采出水中原油对超滤膜的污染问题,以延长超滤膜的使用寿命。常用的超滤预处理工艺有混凝沉降、多介质过滤、生化,其中生化工艺对原油的去除较为彻底,能耗较低,是一种较为理想的超滤预处理工艺。油田采出水利用生化双膜工艺制备锅炉用水技术尚未大规模推广,笔者[7-8]通过近2年的生化超滤工艺和7个月的生化双膜工艺研究发现,油田采出水利用生化双膜工艺制备锅炉用水,实现采出水的资源化利用是非常有前景的,既具有经济效益,又具有社会效益。
在之前的研究[9]中已对预处理及生化工艺进行了详细介绍。本研究重点研究了超滤进水悬浮物与超滤膜污染之间的关系,分别考察了反渗透进水压力、进水温度对产水率、膜通量和透盐率的影响。
1. 水质分析及工艺流程
1.1 水质分析
对采出水的水质进行了多次检测,水质较为稳定:pH=7.55、温度为48 ℃、SS为50 mg∙L−1、含油量为127 mg∙L−1、COD为376 mg∙L−1、BOD为125 mg∙L−1、
HCO−3 为614 mg∙L−1、总硬度为1 400 mg∙L−1、TDS为18 100 mg∙L−1、电导率为30 348 μs∙cm−1。以上结果表明,采出水具有高含油、高矿化度、高COD的特点,将采出水用于锅炉给水必须进行脱盐,脱盐采用的工艺为反渗透,反渗透对进水水质有一定的要求,因此,需要对采出水进行降温、除油、降COD、降悬浮物等预处理。1.2 工艺流程
整套流程包括预处理、生化、超滤、反渗透4个部分,超滤前部分自2018年6月开始运行,2019年10月接入反渗透流程,整套工艺流程如图1所示。
1)预处理包括气浮和降温2个单元。来水首先进行气浮工艺,处理能力为10 m3∙h−1,可去除大部分含油和悬浮物,降低生化部分负荷。风式冷却塔将来水的温度由48 ℃降低到35 ℃以下,为微生物提供合适的生长温度。生化采用的是MBBR工艺,生化池的有效体积为100 m3。加入填料40 m3,材质为HDPE,直径为25 mm,高为10 mm。活性污泥为2 000 mg∙L−1,功能菌种的发酵液为6 m3,初期加入碳源、氮源,7 d后生化运行正常,不再加入碳氮等营养物质。生化曝气采用的是罗茨风机,风量为4 m3∙min−1,沉降采用拉美兰沉降池,停留时间为2 h。连续检测生化后采出水的含油量,并与来水和气浮后对比。
2)超滤采用PVDF管式中空纤维膜,过滤精度为30 nm,过滤方式采用的是死端过滤,超滤综合产水率大于97%。在线检测超滤进水压力、浓水压力、产水压力,并计算跨膜压差。每2 d人工检测1次超滤进水悬浮物,记录同一时间的跨膜压差,分析悬浮物对膜污染的影响。不定期检测超滤产水含油量、悬浮物和pH。
跨膜压差根据式(1)进行计算。
ΔP=(P1+P2)/2−P3 (1) 式中:ΔP为跨膜压差,MPa;P1为进水压力,MPa;P2为浓水压力,MPa;P3为产水压力,MPa。
3)反渗透采用的是陶氏提供的专用反渗透膜。进水泵为固定频率,最高可提供2.3 MPa的进水压力,通过控制浓水阀门调节进水压力。通过调节风式冷却塔和系统进水量调节整个系统水温。在线检测系统的进水压力、进水量、产水量、浓水量、温度、电导率,并计算产水率和膜通量。分析进水压力、进水温度与产水率、膜通量、透盐率的关系。不定期检测反渗透产水的含油量、悬浮物、矿化度、硬度和pH。
反渗透过程中膜通量根据式(2)进行计算。产水率根据式(3)进行计算。
Jw=A(ΔP−ΔPs) (2) 式中:Jw为膜通量,L·(m2·h)−1;A 为纯水渗透系数;ΔP为膜两侧压力差,MPa;ΔPs为膜两侧渗透压差,MPa。
K=0.001JwS/Q (3) 式中:K为产水率;Jw为膜通量,L·(m2·h)−1,S为膜面积,m2;Q为进水量,m3·h−1。
2. 结果与讨论
2.1 采出水经过预处理和生化后含油量的变化
采出水经过气浮和生化后的含油量指标变化如图2所示。来水平均含油量为127 mg∙L−1;气浮出水平均含油量为5.14 mg∙L−1;生化出水平均含油量为0.63 mg∙L−1。
气浮可以去除大部分原油,去除率为96.0%,剩余的4%原油为乳化油和溶解油,均匀分布在采出水中,原油直径小于10 µm,如图3所示。这部分原油利用絮凝和其他常规的方法难以去除,而功能性菌种具有较高的浓度和较大的比表面积,可以比较彻底地降解这部分剩余原油,降解率为3.6%。
2.2 超滤跨膜压差的变化
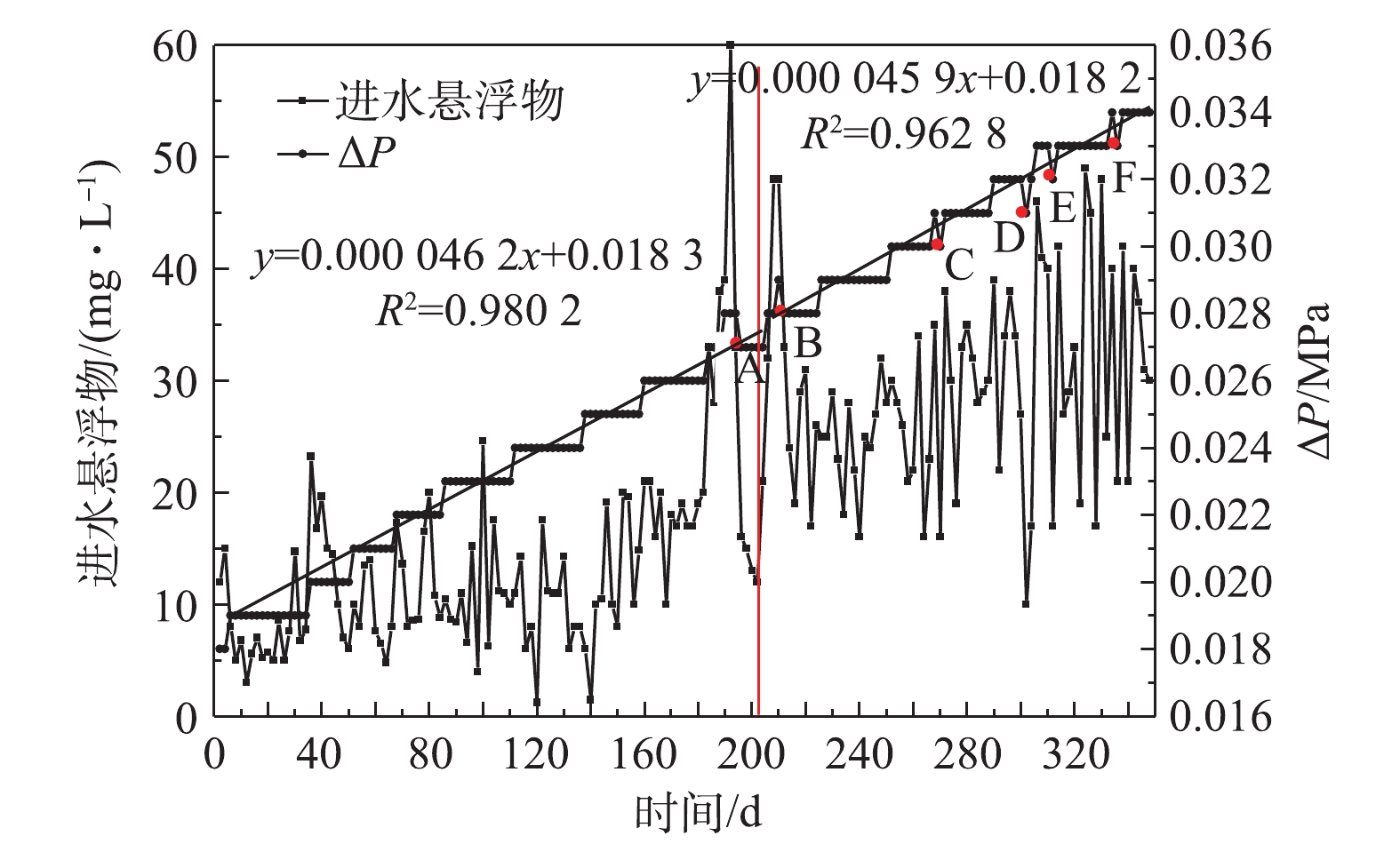
每2 d取一组跨膜压差,跨膜压差的变化如图4所示。实验总共选取了174组数据,由于来水水源某些参数的变化,导致生化后采出水的悬浮物含量增加。前102组数据为来水水源变化前数据,进水悬浮物平均为13.16 mg∙L−1,ΔP的增加速度为0.000 046 2 MPa·d−1,即每年增加0.016 9 MPa,后72组数据为来水水源变化后数据,悬浮物平均为29.38 mg∙L−1,ΔP的增加速度为0.000 045 9 MPa·d−1,即每年增加0.016 8 MPa。对于生化处理后的油田采出水,超滤进水中悬浮物的数量与ΔP的增加速度无关。即在一定范围内,超滤膜的污染速度与进水悬浮物的数量无关。
跨膜压差为超滤膜运行的重要指标之一,其增大速度主要表征超滤膜污染的程度,一般跨膜压差达到0.06 MPa需要对超滤膜进行化学清洗,那么第1次化学清洗,需要的时间为(0.06-0.018 2)/0.016 8 = 2.5 a。由此可见,经过生化处理后的采出水悬浮物虽然较高,但是对超滤膜污染程度较小。
在运行过程中,跨膜压差A、B、C、D、E、F等6个点较前一数据降低了0.001 MPa,原因是由于这6个点对应的悬浮物较前一数据均有较大幅度的波动。由此可见,进水悬浮物数值短时间较大波动会引起跨膜压差暂时增高或降低,当悬浮物数值正常后,跨膜压差可以恢复到前期水平。
2.3 进水压力、进水温度与产水率、膜通量、透盐率的关系
1)通过调节浓水阀调节进水压力,产水率及膜通量的变化如图5所示,透盐率的变化如图6所示。产水率随着进水压力的增大而增加,进水压力每增加0.1 MPa,产水率增加13%~37%,膜通量增加9%~33%。根据LONSDALE等[10]提出的溶解-扩散模型,进水压力增加的同时,跨膜压差增加,导致Jw增大。在膜通量Jw增加的同时,Q减小,K增大,并且K增大的速度大于Jw增大的速度。透盐率随着进水压力的增大而减小,进水压力每增加0.1 MPa,透盐率减小3%~14%。
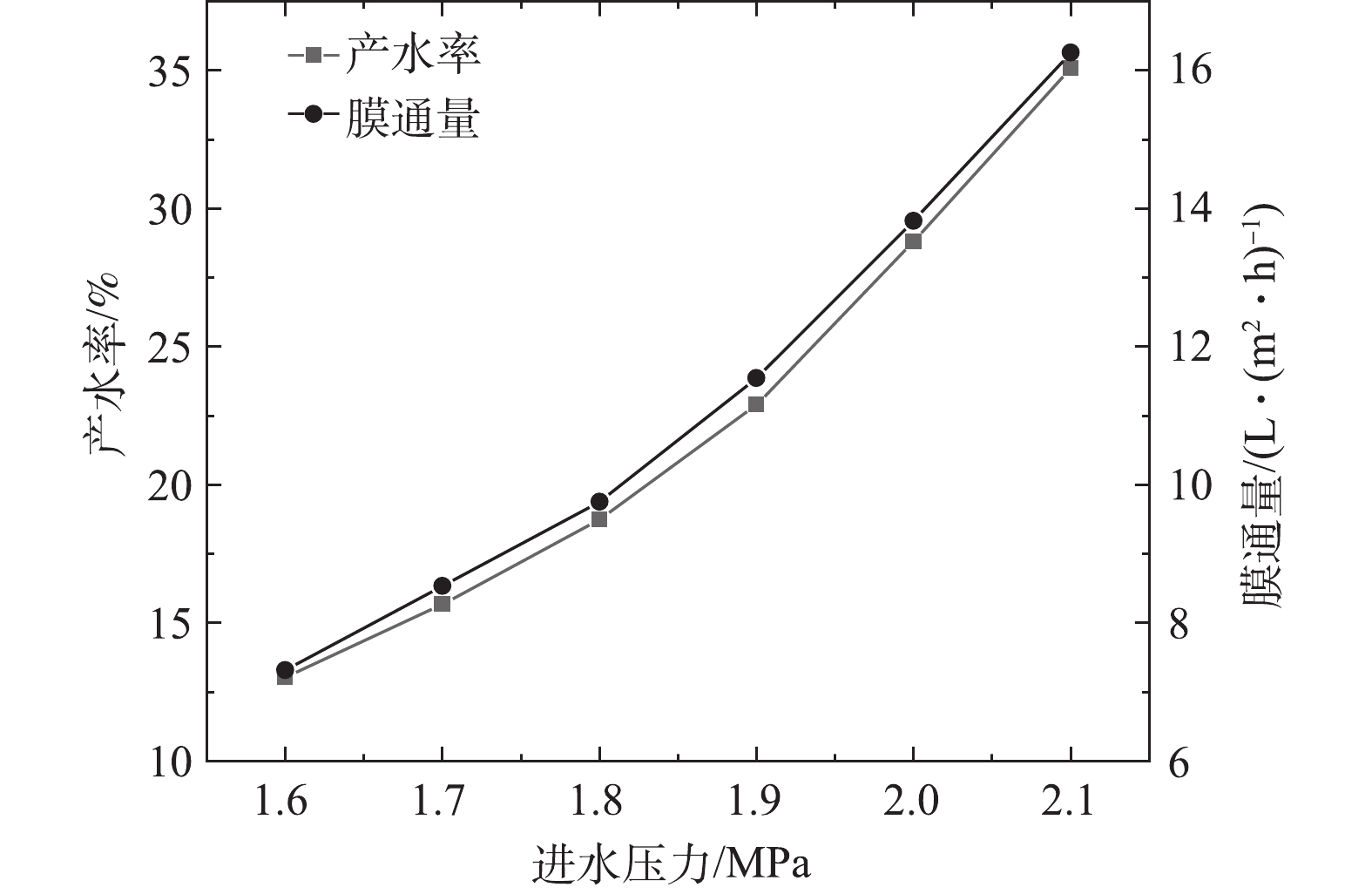 图 5 进水压力与产水率、膜通量的关系(30 ℃)Figure 5. The relationship between influent pressure, water yield and membrane flux (30 ℃)
图 5 进水压力与产水率、膜通量的关系(30 ℃)Figure 5. The relationship between influent pressure, water yield and membrane flux (30 ℃)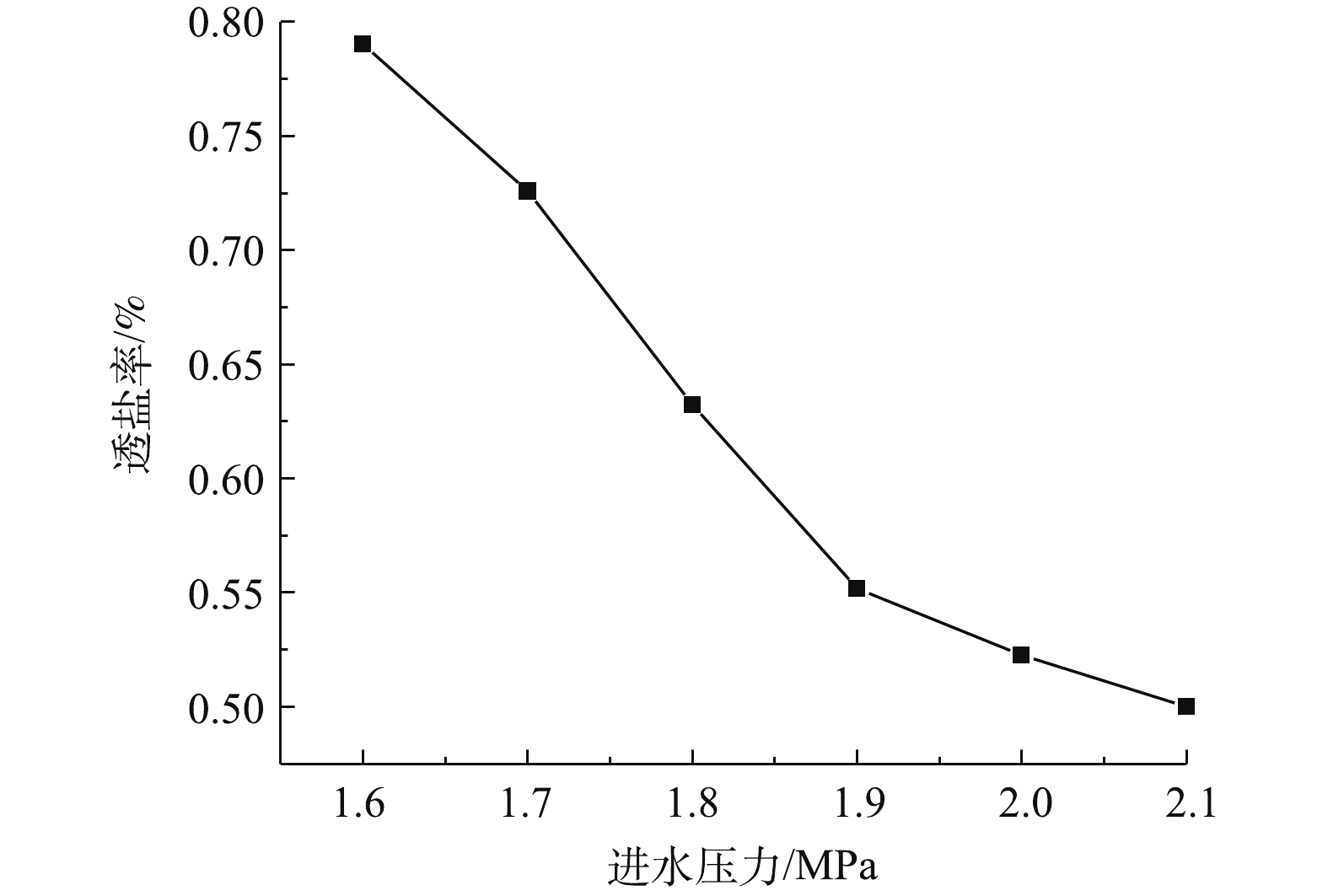 图 6 进水压力与透盐率关系(30 ℃)Figure 6. The relationship between influent pressure and salt permeability (30 ℃)
图 6 进水压力与透盐率关系(30 ℃)Figure 6. The relationship between influent pressure and salt permeability (30 ℃)增加进水压力的方式有2种:方式A,调节浓水阀,减小浓水流量;方式B,增加进水泵频次。进水压力增加的同时可以带来其他参数的变化,结果如表1所示。本研究采用方式A提高进水压力。
表 1 不同调节方式提高进水压力对比Table 1. Comparison of the increase of inlet water pressure responding to different regulation methods调节方式 进水压力 浓水压力 进水量 浓水量 产水量 产水率 膜通量 透盐率 A 增大 增大 减小 减小 增大 增大 增大 减小 B 增大 增大 增大 增大 增大 增大 增大 减小 | Show Table DownLoad:
CSV
DownLoad:
CSV
有研究[11]表明,采用方式A增加进水压力可以提高透盐率,与本实验结果相反,文献中关于浓差极化变化的观点无法解释本实验的现象。有研究[12-18]表明,采用方式B增加进水压力,进水量、浓水量和产水率随之增加,浓水量的增加导致了膜表面浓差极化现象减弱,因此进水侧膜表面离子浓度减小,从而导致产水的离子浓度降低,即透盐率降低。但方式B增加进水压力导致浓差极化减小的结论需要论证,浓差极化的变化取决于膜表面水流的径向速度和纵向速度,径向速度变大可增强浓差极化现象,纵向速度变大可减弱浓差极化现象。如表2所示,2种方式的产水率均有所增大,因此,V径/V纵值均增大。在方式A和方式B中,提高进水压力均会导致浓差极化现象增强。
表 2 不同调节方式对膜表面水流速度影响Table 2. The effect of different regulating methods on the flow velocity of membrane surface调节方式 V径 V纵 V径/V纵 A 增大 减小 增大 B 增大 增大 增大 | Show TableDownLoad:
CSV
笔者认为,根据选择吸附毛细管理论,RO膜表面的浓差极化现象增加导致膜表面的各种离子浓度增加,相互排斥作用加强,因此,各种离子透过RO膜难度增大。随着进水压力的增大,膜通量和透盐量同时增加,而透盐量增加的速度小于膜通量增加的速度,因此,产水的含盐量减小,透盐率减小。本研究结果表明,在一定范围内,如果只考虑透盐率因素,增加反渗透工艺的浓差极化可以降低透盐率。综上所述,在一定范围内,提高进水压力既可以增加产水率,又可以降低透盐率,有利于整套系统的运行。
2)通过调节风式冷却塔和系统进水量改变RO进水温度,产水率及膜通量的变化如图7所示,透盐率的变化如图8所示。在压力不变的情况下,产水率随着水温的升高而增加,进水温度每升高1 ℃,产水率增加约0.25%,膜通量增加约0.47%,随着温度升高,水的粘度变小,因此,膜通量和进水量均有增加。根据式(3)可知,进水量Q随着温度的增加而升高,因此,膜通量Jw增加的速度大于产水率K增加的速度。在压力不变的情况下,透盐率随着水温的升高而升高,进水温度每升高1 ℃,透盐率增加约6.7%。水温的升高同样会导致透盐率的增大,这主要是因为盐分透过膜的扩散速度会因水温的升高而加快[19]。
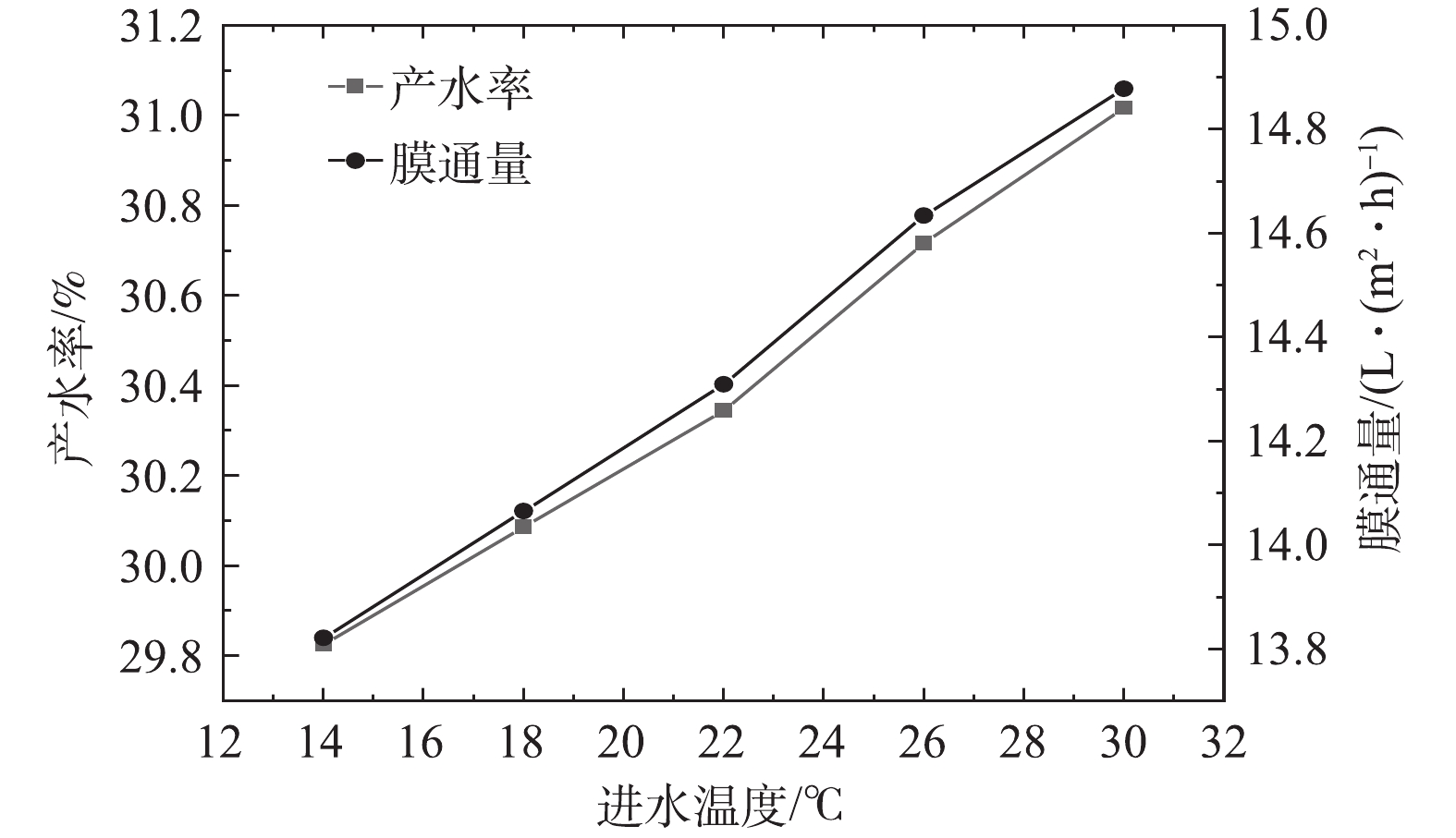 图 7 进水温度与产水率、膜通量的关系(2.0 MPa)Figure 7. The relationship between influent temperature and water yield, membrane flux (2.0 MPa)
图 7 进水温度与产水率、膜通量的关系(2.0 MPa)Figure 7. The relationship between influent temperature and water yield, membrane flux (2.0 MPa)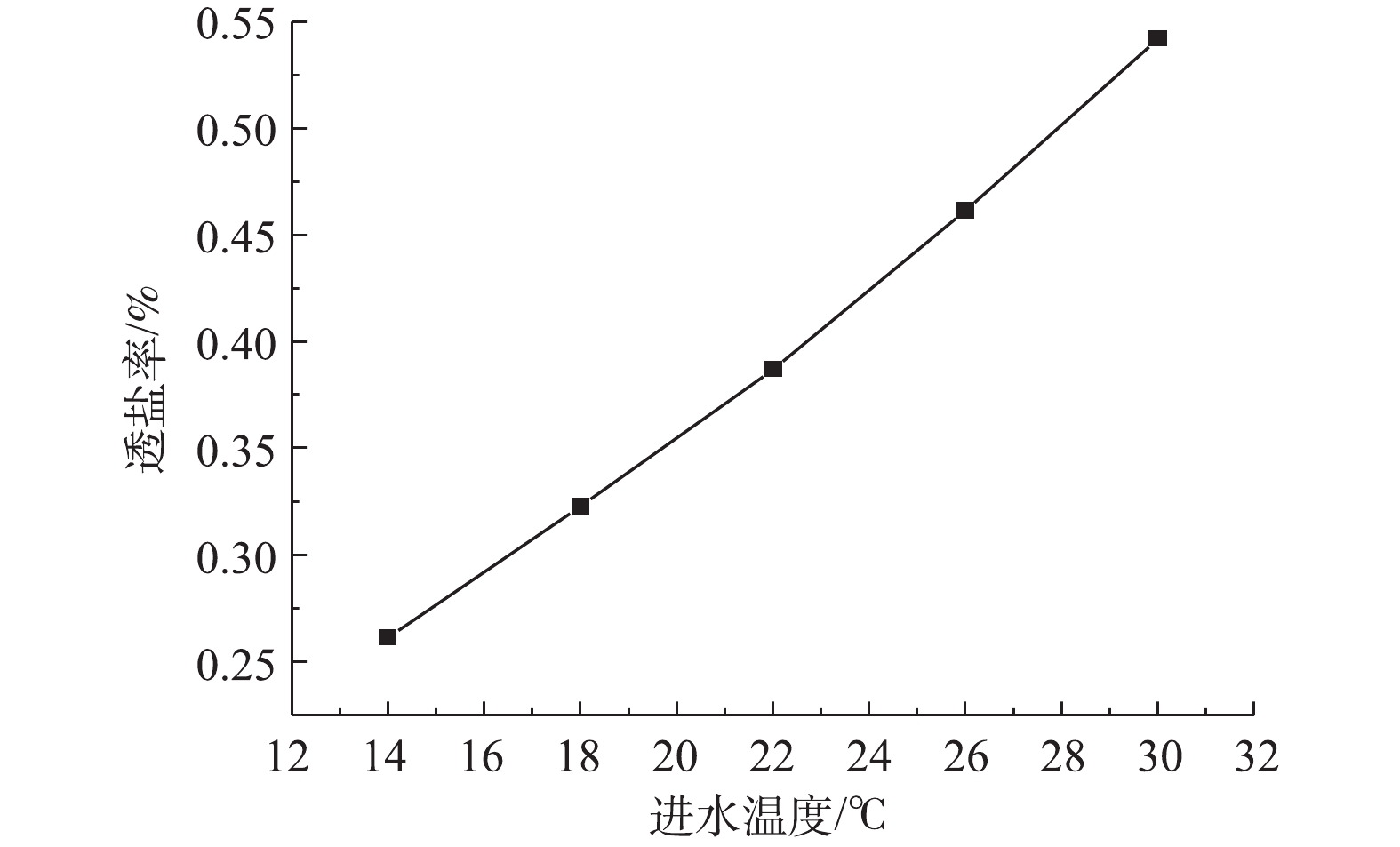 图 8 进水温度与产水率、膜通量的关系(2.0 MPa)Figure 8. The relationship between influent temperature and salt permeability (2.0 MPa)
图 8 进水温度与产水率、膜通量的关系(2.0 MPa)Figure 8. The relationship between influent temperature and salt permeability (2.0 MPa)综上所述,在一定范围内,提高RO系统进水温度可以增加产水率和透盐率,整套系统可以根据产水水质和水量的要求以调节进水温度。
2.4 生化双膜工艺各个节点的指标变化
对整个流程各个节点的指标进行检测,并与锅炉给水[20]指标进行对比,结果如表3所示。含油量、悬浮物和矿化度等指标完全满足锅炉给水的要求。
表 3 工艺节点水质变化Table 3. Changes in the water quality of the process nodes工艺节点 含油量/(mg∙L−1) 悬浮物/(mg∙L−1) 矿化度/(mg∙L−1) 硬度/(mg∙L−1) pH 来水 127 50 18 100 1 440 7.55 生化 0.63 19.92 7.32 超滤 0.2 0.2 7.31 RO 0 0 81 0.36 6.86 锅炉给水 ≤2 ≤2 ≤7 000 ≤0.1 7.5~11 | Show TableDownLoad:
CSV
pH由7.31下降到6.86,这是因为RO膜可以脱除溶解性的离子而不能脱除溶解性的气体,产水中的CO2和进水中CO2的基本相等,而产水中
HCO−3 大幅度减少,由于水中的CO2和HCO−3 存在平衡方程(式(4)),因此,原有的平衡被打破,平衡方程式向右移动,导致H+浓度增加,故导致pH下降。CO2+H2O⇌HCO−3+H+ (4) RO水中的硬度和pH未达到锅炉给水的标准,使用常规的树脂交换可以除掉残余硬度,用液碱可以调节pH,在此不做深入研究。
3. 结论
1)油田采出水经过气浮后,剩余的原油以乳化油和溶解油的形态存在,直径小于10 µm,经过生化处理后,水中的剩余原油为0.63 mg∙L−1,满足超滤膜的进水要求。
2)生化处理后的油田采出水,对超滤膜的污染程度很小,在一定范围内,水中的悬浮物含量与膜污染速度无关,跨膜压差ΔP的增加速度为0.000 046 2 MPa·d−1;进水悬浮物数值短时间较大波动会引起跨膜压差的暂时升高或降低,当悬浮物数值恢复正常后,跨膜压差可以恢复到前期水平。
3)增大反渗透进水压力会导致产水率增加、膜通量增加、透盐率降低,产水率和膜通量增加是膜两侧压力差增大的结果,透盐率降低,是浓差极化加强导致的结果;升高进水温度会导致产水率增加、膜通量增加、透盐率增加,产水率和膜通量增加是水粘度变小的结果,透盐率升高,是水中的离子扩散速度变大的结果。
4)油田采出水利用生化双膜工艺制备锅炉用水的方法是可行的。处理后的水质含油量为0 mg∙L−1、悬浮物为0 mg∙L−1、矿化度为81 mg∙L−1,可以达到锅炉给水的要求;而硬度和pH达不到锅炉给水的标准,需要进一步处理。
-
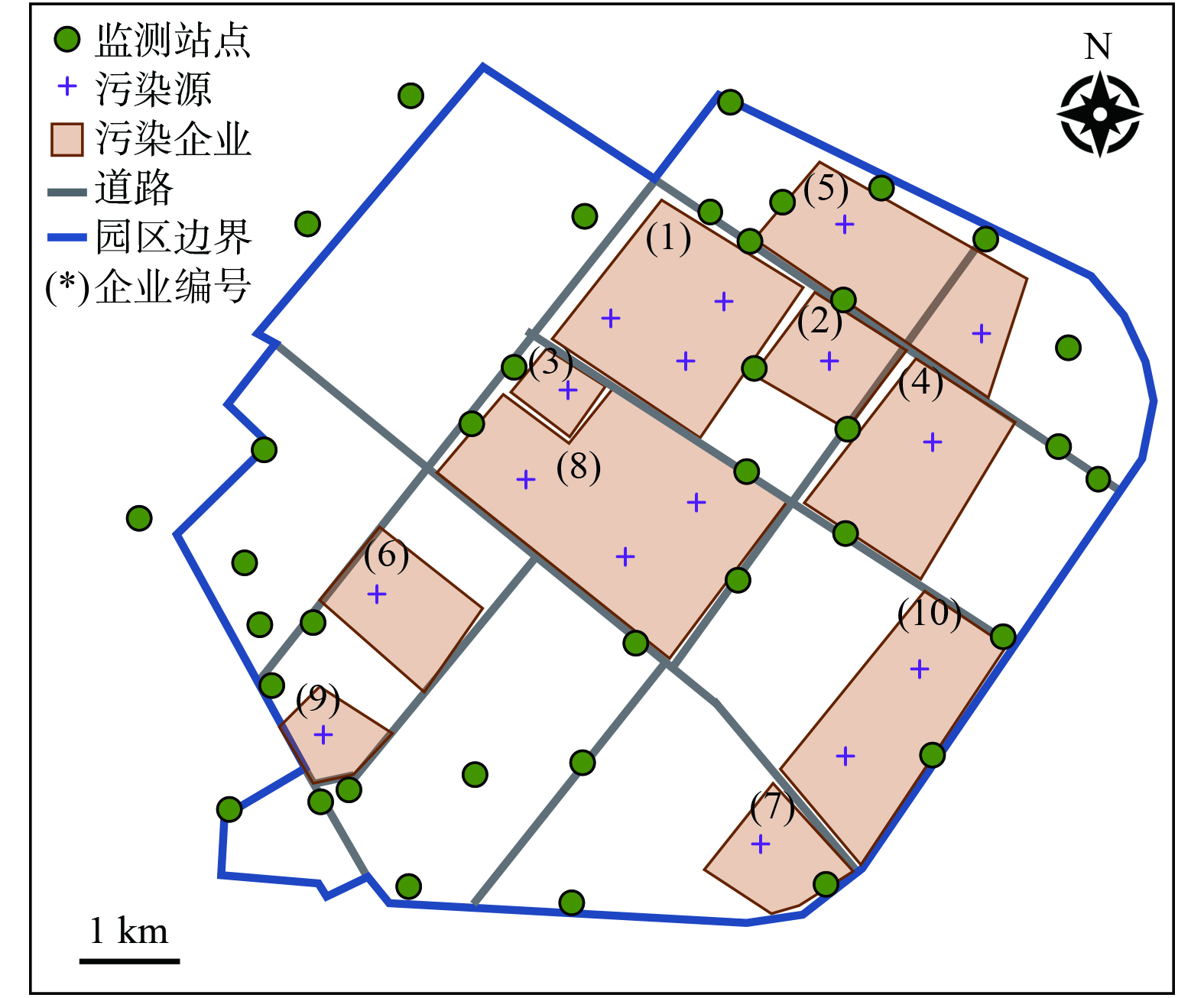
图 1 示例园区污染源及监测站点布局图
Figure 1. Layout of pollution sources and monitoring stations in sample park
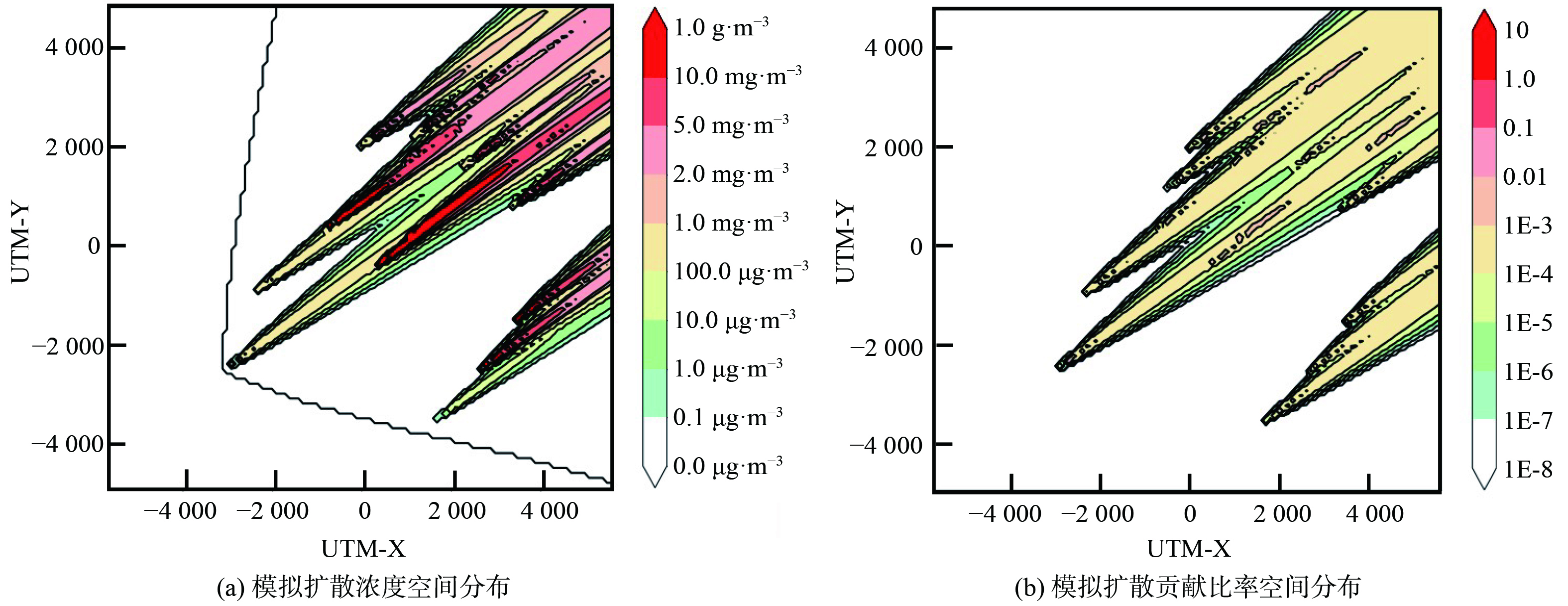
图 2 示例园区2023年1月1日00时模拟扩散浓度及贡献比率空间分布
Figure 2. Simulated diffusion concentration (left) and contribution ratio (right) spatial distribution at 00:00 on January 1, 2023 of sample park
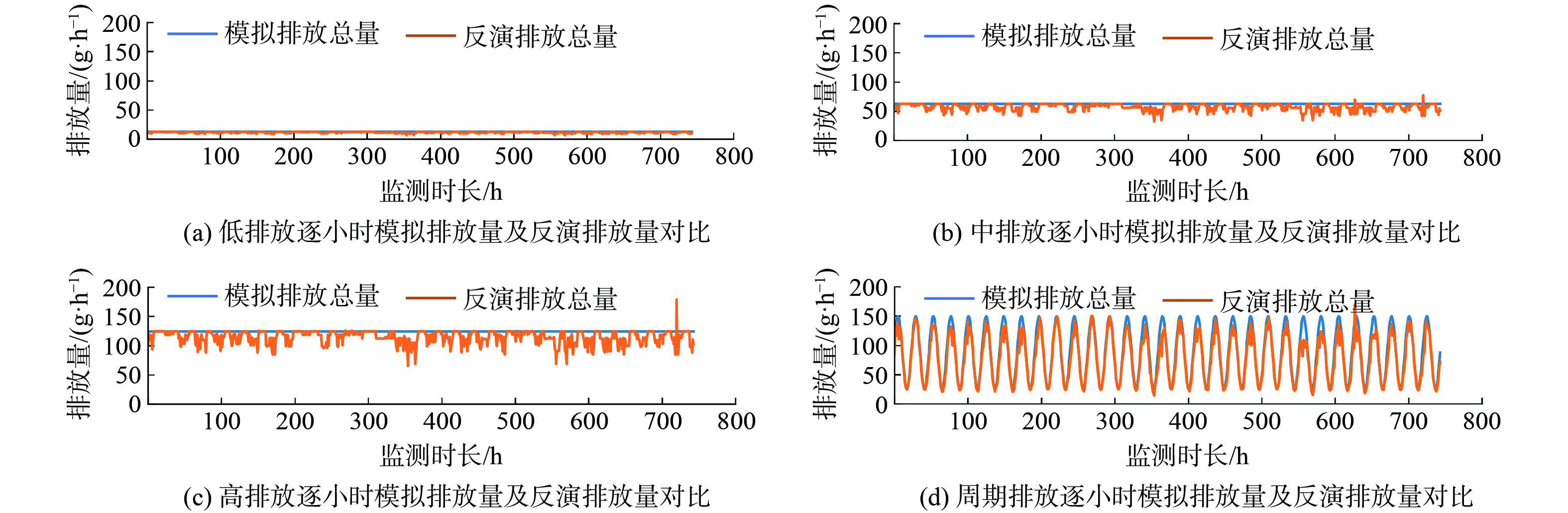
图 3 不同排放情景下逐小时模拟排放量及反演排放量对比
Figure 3. Comparison of hourly simulated emissions and inverted emissions under different scenarios
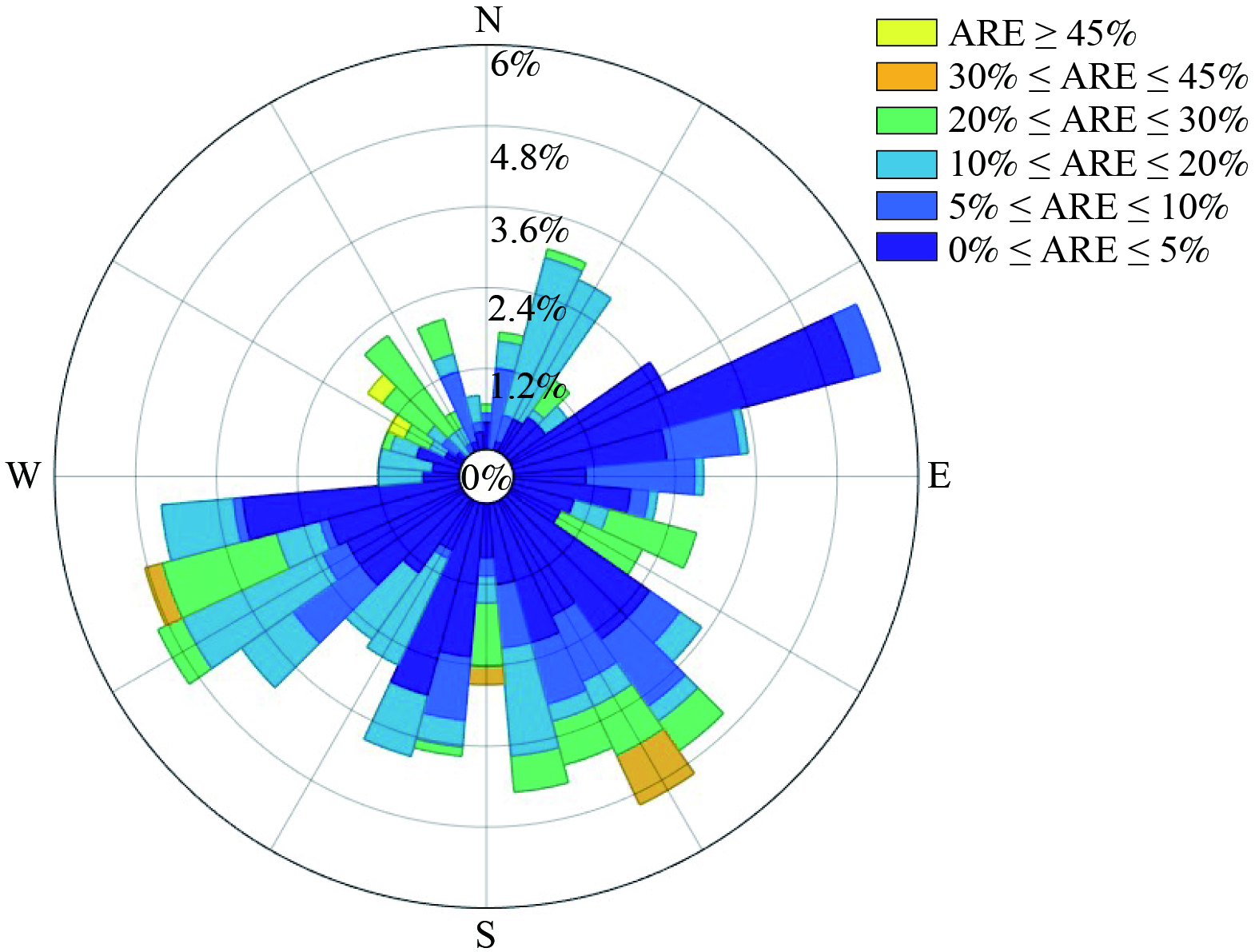
图 4 排放总量反演绝对相对误差 (ARE) 与风向关系
Figure 4. Relationship between absolute relative error (ARE) of total emission inversion and wind direction
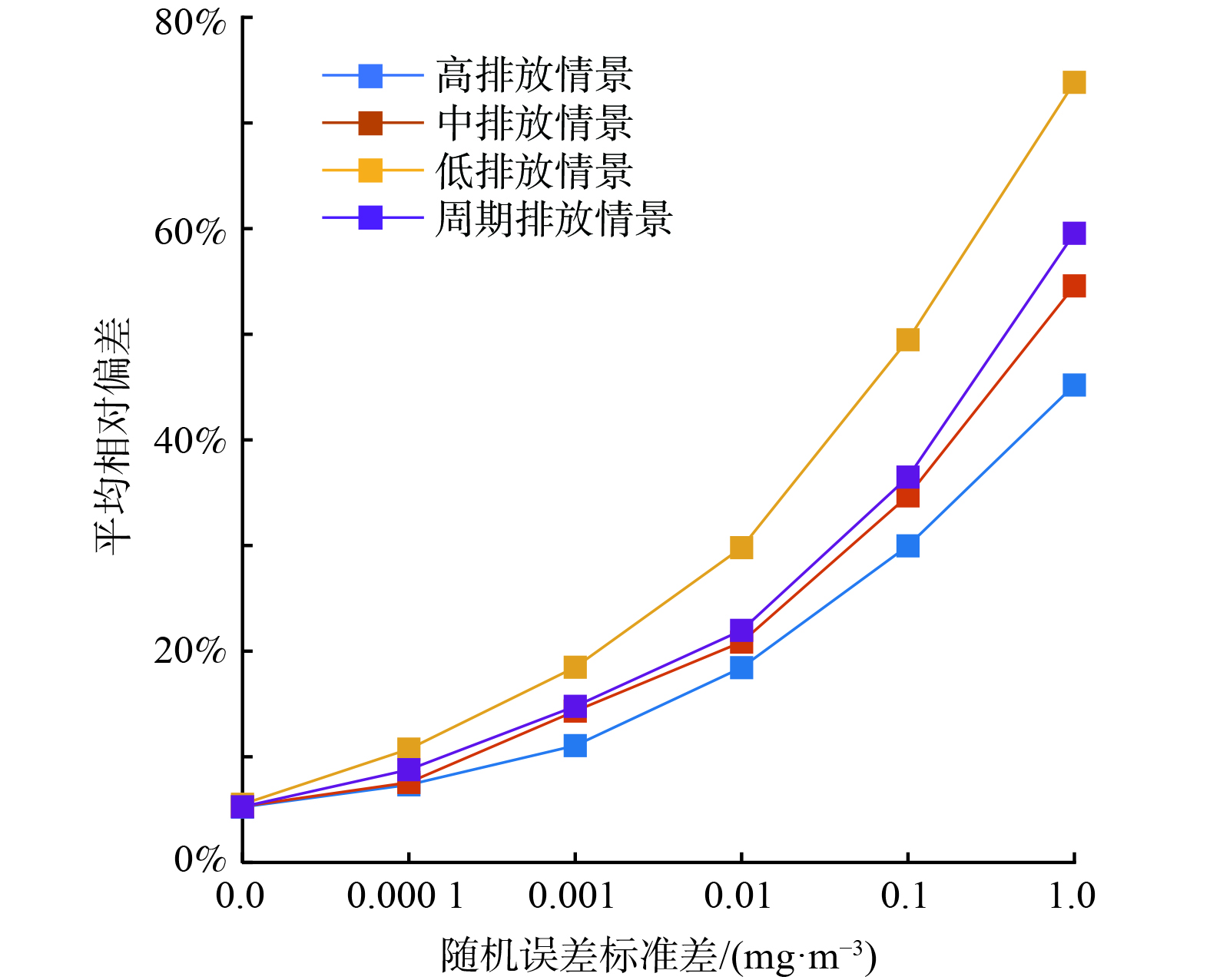
图 6 不同排放情境下反演精度与随机误差强度的关系
Figure 6. Relationship between inversion accuracy and random error intensity under different emission scenarios
表 1 示例园区污染源相对位置及VOCs年排放量
Table 1. Relative location of pollution sources and annual emissions of VOCs in sample park
企业编号 点位编号 相对位置 VOCs年排放量 X/m Y/m 许可排放量/(t·a−1) 统计核算量/(t·a−1) (1) 1-1 −105.69 1 939.64 558.06 305.68 1-2 694.15 1 513.34 1-3 1 080.49 2 126.93 (2) 2-1 2 191.57 1 535.64 231.22 52.70 (3) 3-1 −567.09 1 159.14 0.00 0.00 (4) 4-1 3 307.64 732.23 257.24 2.46 (5) 5-1 2 328.21 2 950.21 188.13 11.10 5-2 3 805.85 1 865.68 (6) 6-1 −2 494.02 −1 017.60 16.17 0.84 (7) 7-1 1 605.90 −3 561.35 1.01 0.46 (8) 8-1 −945.73 223.88 1 855.47 — 8-2 100.86 −572.14 8-3 842.90 27.32 (9) 9-1 −3 033.36 −2 506.92 23.64 0.14 (10) 10-1 2 488.31 −2 613.47 801.12 — 10-2 3 236.00 −1 661.56
下载: 导出CSV
表 2 工业园区大气污染排放总量反演精度模拟评估
Table 2. Simulation and Evaluation of the Precision of Inversion of Total Air Pollution Emissions in Industrial Parks
情景模式 背景浓度反演偏差 (MARE) 小时排放量反演偏差 (MARE) 低排放情景 (0.00±0.00)% (5.39±7.43)% 中排放情景 (0.00±0.00)% (5.33±7.34)% 高排放情景 (0.00±0.00)% (5.54±7.50)% 周期排放情景 (0.00±0.00)% (5.33±7.34)%
下载: 导出CSV
表 3 排放总量反演精度与工业园区大气稳定度的关系
Table 3. Relationship between the accuracy of total emission inversion and the atmospheric stability of industrial parks
大气稳定度 小时数 平均绝对相对偏差 (MARE) A 16 (0.00±0.01)% B 156 (0.62±2.16)% C 3 (3.40±5.88)% D 140 (1.03±3.22)% E 151 (6.07±6.67)% F 278 (10.08±8.12)%
下载: 导出CSV
表 4 不同布点方案下模型逐小时反演精度评估
Table 4. Hourly Inversion accuracy evaluation of models under different layout schemes
布点方案 监测站点数 平均绝对相对偏差 高排放情景 中排放情景 低排放情景 周期排放情景 两点布设 2 (75.55±34.42)% (75.68±34.20)% (76.06±33.83)% (75.56±34.39)% 简化布设* 40 (5.39±7.43)% (5.33±7.34)% (5.54±7.50)% (5.33±7.34)% 网格化布设 76 (0.36±1.55)% (0.39±1.69)% (0.48±2.28)% (0.40±1.83)% *注:本文2.1节采用简化布设条件,故本行结果采用表2中的数据。
下载: 导出CSV
-
[1] 白璐, 乔琦, 张玥. 工业污染源产排污核算模型及参数量化方法[J]. 环境科学研究, 2021, 34(9): 2273-2284. [2] 江苏省打好污染防治攻坚战指挥部办公室. 江苏省工业园区(集中区)污染物排放限值限量管理工作方案(试行)[EB/OL]. [2021-7-19]. https://huanbao.bjx.com.cn/news/20210811/1169162.shtml, 2021. [3] 吴文华. 污染物排放总量的技术核算方法研究[J]. 中国资源综合利用, 2018, 36(3): 179-181. [4] 何雪芹, 周洁, 陈志诚, 等. 环境统计中污染物产生量排放量核算方法的探讨[J]. 科技创新导报, 2020, 17(13): 135-136. [5] 生态环境部. 排放源统计调查产排污核算方法和系数手册[EB/OL]. [2021-6-11] W020210624327149500026. pdf. ((mee. gov. cn). (mee. gov. cn). [6] 胡瑞, 张学伟. 环境统计中污染物产生量排放量核算方法的探讨[J]. 科技视界, 2012(34): 151. [7] 杨喆, 李涛, 杨松柏, 等. 同时考虑监测和物料衡算的环境保护税税基核定方法[J]. 环境污染与防治, 2019, 41(5): 608-610. [8] 郑伟, 孙亚梅, 刘伟. 燃煤电厂大气汞排放量核算方法研究[C]//2017中国环境科学学会科学与技术年会论文集(第一卷). 中国环境科学学会, 2017. [9] 高新伟, 李瑶. 火电企业大气污染物排放量核算方法研究[J]. 环境科学与管理, 2022, 47(12): 70-75. [10] 路学军, 展卫红. 物料衡算法在工业源污染物排放量核算中的应用探讨[J]. 科学之友, 2009(33): 153-155. [11] 张久凤. 基于监测数据的源强反算算法研究及应用[D]. 青岛: 中国石油大学, 2011. [12] 伯鑫, 丁峰, 徐鹤, 等. 大气扩散CALPUFF模型技术综述[J]. 环境监测管理与技术, 2009(3): 9-13. [13] CARLTON A G, BHAVE P V, NAPELENOK S L, et al. Model representation of secondary organic aerosol in CMAQv4.7[J]. Environmental Science & Technology, 2010, 44(22): 8553-8560. [14] 易俊华, 许泉立. GIS环境下基于高斯烟羽模型的大气点源污染扩散模拟研究[J]. 测绘与空间地理信息, 2022, 45(8): 73-76. [15] 制定地方大气污染物排放标准的技术方法GB/T 3840-1991[S]. 国内-国家标准-国家市场监督管理总局 CN-GB, 1991. (https://www.mee.gov.cn/image20010518/5332.pdf). [16] 沈泽亚, 郎建垒, 程水源, 等. 典型耦合优化算法在源项反演中的对比研究[J]. 中国环境科学, 2019, 39(8): 3207-3214. [17] CUI J, LANG J, CHEN T, et al. Investigating the impacts of atmospheric diffusion conditions on source parameter identification based on an optimized inverse modelling method[J]. Atmospheric Environment, 2019, 205: 19-29. doi: 10.1016/j.atmosenv.2019.02.035 [18] HAUPT S E. A demonstration of coupled receptor/dispersion modeling with a genetic algorithm[J]. Atmospheric Environment, 2005, 39(37): 7181-7189. doi: 10.1016/j.atmosenv.2005.08.027 [19] HAUPT S E, BEYER-LOUT A, LONG K J, et al. Assimilating concentration observations for transport and dispersion modeling in a meandering wind field[J]. Atmospheric Environment, 2009, 43(6): 1329-1338. doi: 10.1016/j.atmosenv.2008.11.043 [20] 生态环境部. 环境空气挥发性有机物气相色谱连续监测系统技术要求及检测方法 HJ 1010-2018[S/OL]. https://www.mee.gov.cn/ywgz/fgbz/bz/bzwb/jcffbz/201901/t20190105_688615.shtml. [21] 国家质量监督检验检疫总局. 《挥发性有机化合物光离子化检测仪校准规范》(JJF 1172-2007)[S]. 北京: 中国标准出版社, 2007. -
 点击查看大图
点击查看大图
计量
- 文章访问数: 2446
- HTML全文浏览数: 2446
- PDF下载数: 78
- 施引文献: 0










































