


 下载:
下载:





-
近年来,场地土壤污染问题越来越受到公众和社会的关注[1-2]。我国在汲取国外近40年治理经验的基础上,提出了“预防为主,保护优先,风险管控”的场地土壤污染防治策略,初步形成了包括法律、法规、导则、指南和规章在内的一整套相对较为完善的场地土壤风险管控体系。尽管如此,我国场地土壤污染风险管理依然处于刚刚起步阶段,尤其是土壤污染底数不清。目前,主要采用现场踏勘、人员访谈、资料分析并结合日常监管等方式进行疑似污染场地识别,但是,这些传统方式的精准性不高、科学性不足、全面性不够,工作效率较低。
近年来,大数据在生态环境保护领域的研究与应用得到了快速发展[3-10],特别是利用大数据开展土壤污染风险识别与风险管控的研究越来越受到研究者的关注[11-13]。针对非结构化调查报告,利用自然语言处理,自动提取和生成结构化土壤污染信息,实现土壤数据分析已见报道[11]。有学者基于第二次土地调查数据,结合高程、地貌、土地类型等17个环境协变量数据,利用随机森林、极端梯度提升等,绘制了高精度的全国土壤pH空间分布地图,并推测了土壤重金属环境容量[12]。值得一提的是,JIA等[13]考虑到政府部门间存在数据孤岛、数据共享难度大等问题,以长江三角洲地区为研究区,基于兴趣点(Point Of Interest)的非结构化文本数据,利用多项式朴素贝叶斯算法,识别了疑似土壤污染企业,对场地调查评估、风险管控等环境管理提供了良好的决策支撑作用。但是,该研究仅能识别《国民经济行业分类》(GB/T 4754-2017)中大类行业企业,利用企业名称构建有语义词汇库,且未构建无语义词汇库[13]。识别中类甚至小类行业以提高预测精度、增加有语义词汇库库容以克服朴素贝叶斯算法的过度拟合和零概率现象、构建无语义词汇库以降低维数和提高运算速度等已成为疑似土壤污染企业识别中迫切需要解决的问题。
鉴于此,本研究以南方某地级市为研究区,借助大数据平台,基于自然语言处理和机器学习,尝试利用改进型朴素贝叶斯算法,预测POI数据中企业所属中类行业类别,识别疑似土壤污染企业,以期为场地污染识别与风险管控实践提供理论依据和设计参数。
全文HTML
-
1)基础数据。国民经济行业分类数据(1 700条):小类行业名称、中类行业名称和分类说明。污染企业数据(62×104条):企业名称、行业类别和经营范围。POI数据(9 900条):企业名称和经纬度坐标。疑似土壤污染行业数据(38条):中类行业名称和特征污染物。日常监管数据(221条):企业名称和经纬度坐标。
2)数据预处理。剔除标点符号、英文字母、数字等词汇;通过pynlpir辅助函数进行降噪;进行唯一性检查、去重、人工补缺和精度归一化处理;利用自行设计的自关联表(表1)对小类行业名称及其分类说明向上聚合至所属中类。
-
1)硬件环境。管理服务器2台,用于CDH Manager管理和Zookeeper分布式协调服务,并作为Hive数据仓库入口;计算服务器4台,作为Impala、Spark的计算节点和Hbase节点,其中2台还用于Zookeeper分布式协调服务,并作为Redis数据库。服务器的核心组件为CPU:12核心、线程数2个/核心、主频2.2 GHz、三级缓存16.5 MB。内存:总容量128 GB、单挑容量16 GB、规格DDR4、工作频率2 400 MHz。磁盘:系统盘容量600 GB、数据盘容量2 TB、接口形式SAS。RAID卡:支持RAID0、RAID1、RAID5、RAID10、RAID50、JBOD等模式。网络:带宽10 Gbps。系统:CentOS 7.4。
2)软件环境。核心组件为JDK 1.8、Python 3.7、Scala 2.11.x、OpenSSL、Niginx、Tomcat、Libgfortran 4.6+、Apache Hadoop 2.x、Apache Zookeeper 3.4.x、Apache Hive 2.1.x、Apache HBase 1.2.x、Hue 3.9.x、Apache Impala 2.12.x、Apache Parquet 2.1.x、Apache Spark 1.6.x、Apache Spark2 2.4.x、Redis 4.x、MongoDB 4.2.x、PostgreSQL 9.4.x、CDH 5.16、ArcGIS 10.2.2、Echart 4.8.0-release。
-
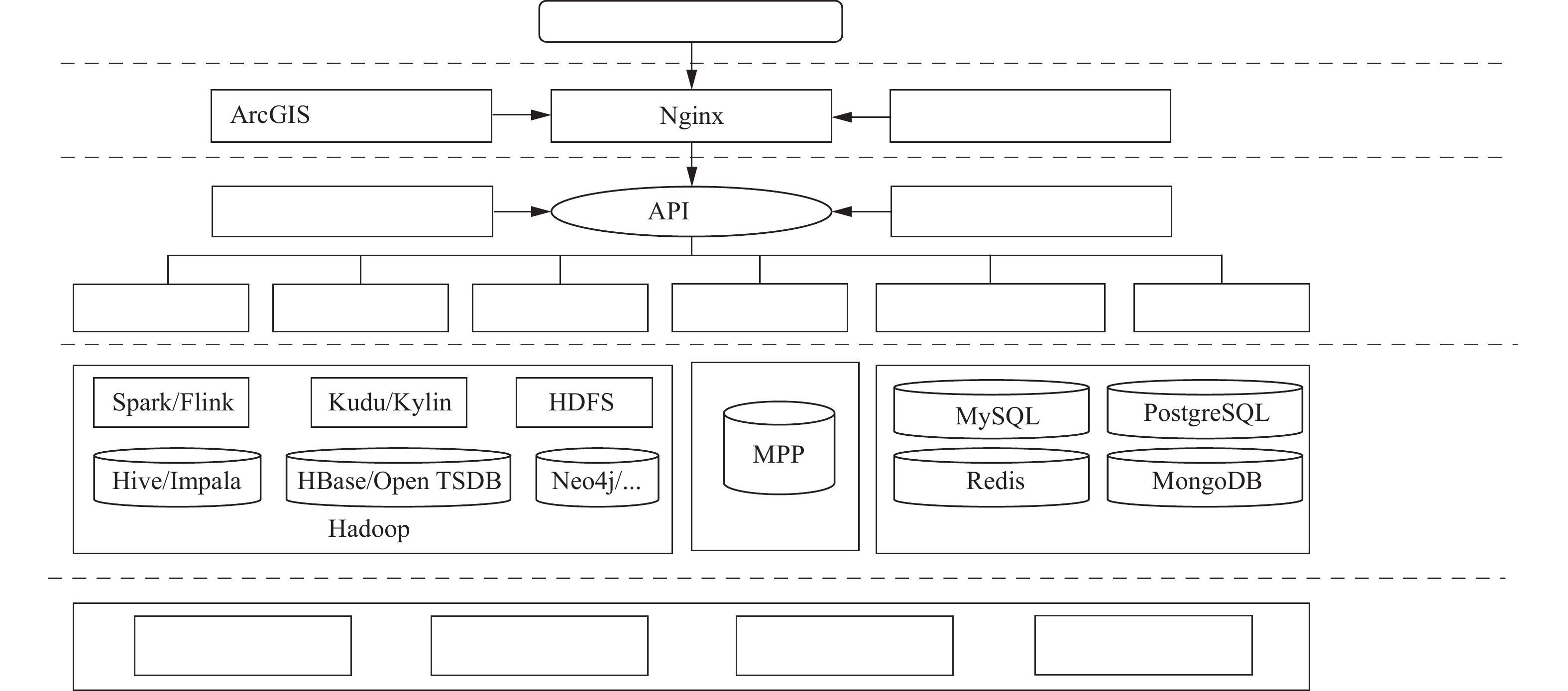
基于大数据存储和处理的需要,于CentOS7.4集群,运用分布式技术,搭建大数据平台架构,主要由数据资源汇聚层、数据平台层、分析处理层、前端展示层和数据访问层等5个功能层组成(图1),能够满足行业分类预测、污染企业识别、ArcGIS平台与大数据平台交互、可视化展示等需求。
-
1)特征工程处理:针对国民经济行业分类数据、污染企业数据和POI数据,首先,采用隐马尔可夫模型[14-15]、Viterbi算法和jieba分词引擎进行中文分词,并采用cut函数提取和剔除地名、“公司”“有限”“有限责任”等对行业类别预测无意义的词汇组成无语义词汇库,剩余的词汇组成有语义词汇库;其次,采用词频-逆文本频率算法[16-17]统计各个样本中位于有语义词汇库内词汇词频,其中min_df下频率值调整为0.15、max_df上频率值调整为0.90;然后,再次人工过滤并剔除出现次数多且对行业类别预测无意义的词汇,并将其增补进无语义词汇库,同时剩余的词汇作为特征词组成最终的有语义词汇库;最后,采用词频-逆文本频率算法重新统计各个样本中特征词词频(式(1)~式(3))。
特征词正向词频(
tfi,j )计算见式(1),特征词逆向文本频率(idfj )计算见式(2),特征词词频(tfidfi,j )计算见式(3)。式中:
tfi,j 为第i个特征词在第j个污染企业名称中的词频;ni,j 为第i个特征词在第j个污染企业名称中的出现次数;∑kni,j 为第j个污染企业名称中全部k个特征词出现次数的总和。式中:
idfj 为第i个特征词的逆向文本频率;|D| 为有语义词汇库内所有污染企业名称的总数;dj 为第j个污染企业名称;|{j:wi∈dj}| 为包含第i个特征词的污染企业名称的总和。式中:
tfidfi,j 为第i个特征词在第j个污染企业名称中的权重;tfi,j 同式(1);tfidfi,j 同式(2)。2)摘要构建:按小类行业,将行业名称和分类说明中由高至低排在前100位的有语义词汇组成热词;然后,利用自关联表对各小类行业的热词向上聚合至所属中类,形成代表中类行业的摘要。
3)行业类别预测模型构建与训练:首先,结合摘要,将特征词与摘要进行匹配,匹配上时将特征词词频乘以权重作为其特征值,匹配不上时则将特征词词频作为其特征值;其次,使用训练数据集训练基于改进型朴素贝叶斯算法的预测模型[18-19](图2),在此过程中,使用10折交叉验证的网格搜索方法调整拉普拉斯平滑法[20]中平滑参数α,使用5次验证集的平均准确率最高值作为最佳参数;最后,通过检验数据集的准确率、召回率和F1值评估模型,获取改进型行业类别预测模型。
4) POI数据的行业类别预测:将POI数据输入已经训练好的改进型朴素贝叶斯模型,预测各企业所属行业。
5)污染企业识别:从POI数据的预测结果中提取疑似土壤污染行业数据涉及的中类行业,将其对应的企业作为疑似土壤污染企业。
-
1)不同行业词云构建:采用隐马尔可夫模型、viterbi算法和jieba分词引擎,对污染企业数据(含企业名称和经营范围)进行中文分词;然后,利用相同词汇累加方法,统计有语义词汇库中词汇出现的次数;最后,使用Python中word cloud库绘制不同行业词云。
2)行业分类预测算法筛选:将污染企业数据集按9∶1比例划分为训练数据集和检验数据集;在此基础上,比较随机森林、XGBoost和朴素贝叶斯3种算法,通过分别比较准确率、召回率和F1值,确定最佳的行业分类预测算法。
3)有语义词汇库构建方法比选:利用企业名称和企业名称+经营范围分别构建有语义词汇库,通过分别比较朴素贝叶斯算法的准确率、召回率和F1值,确定最佳的有语义词汇库构建方法。
4)朴素贝叶斯模型改进:结合摘要,通过比较不同权重和平滑参数α引起的朴素贝叶斯算法的准确率、召回率和F1值,确定改进型朴素贝叶斯模型。
5)行业企业空间分布结果分析:在ArcGIS平台上,以南方某地级市作为研究区,将POI疑似土壤污染企业和日常监管企业分行业进行空间分布,分析行业分类预测和污染企业识别的实际效果。
-
行业分类预测的准确率计算见式(4),行业分类预测的召回率计算见式(5),行业分类预测的F1值计算见式(6)。
式中:P为准确率,预测正确的样本占所有样本的比例;n为所有样本个数;nc为预测正确的样本个数。
式中:R为召回率,预测正确的样本占某个行业所有样本的比例;nc同公式(1);m为某个行业所有样本个数。
式中:F1为综合评价指标值;P同式(4);R同式(5)。
1.1. 基础数据及预处理
1.2. 大数据软硬件环境
1.3. 大数据技术架构
1.4. 基于改进型朴素贝叶斯算法的中类行业类别预测与污染企业识别
1.5. 实验设计
1.6. 数据分析方法
-
针对有语义词汇库中多于40×104个词汇,采用颜色区分词汇,采用字体大小区分出现频率,经统计形成不同土壤污染重点行业词云,部分行业词云见图3。由图3可知,农药制造行业的高频词汇为化工、生物科技、科技;化学药品原料制造行业的高频词汇为制药、药业;合成材料制造行业的高频词汇为科技、材料、化工;基础化学原料制造行业的高频词汇为化工、贸易、商贸;常用有色金属冶炼行业的高频词汇为有色金属、矿业金属;涂料、油墨、颜料及类似产品制造行业的高频词汇为化工、涂料、科技、材料;皮革鞣制加工行业的高频词汇为皮革、皮业、皮革制品;金属表面处理及热处理加工行业的高频词汇为电镀、电镀厂、金属表面。可知,词云有助于初步地认知和感知不同行业特点,并为后续行业分类预测和污染企业识别提供前提基础。
-
随机森林、XGBoost和朴素贝叶斯等行业分类算法引起的准确率、召回率和F1值变化见表2。准确率衡量算法分类结果的准确性,召回率衡量算法分类结果的完整性,而F1值则是综合考虑前述2个因素衡量算法分类结果效果。由表2可知,无论从准确率还是召回率亦或F1值上看,不同算法的分类性能存在一定差异,且朴素贝叶斯算法的性能优于随机森林算法和XGBoost算法。其中,前者比后者在准确率上分别提高了0.07和0.04;在召回率上分别提高0.08和0.07;在F1值上分别提高0.07和0.05。因此,采用朴素贝叶斯算法进行行业分类预测,尽管该算法的性能还有待提高。
-
利用企业名称和企业名称+经营范围分别构建有语义词汇库,2种构建方法引起的朴素贝叶斯算法的准确率、召回率和F1值变化见表3。由表3可知,与仅采用企业名称相比,采用企业名称+经营范围构建有语义词汇库后,朴素贝叶斯算法的准确率、召回率和F1值得到大幅提升,分别提高了0.23、0.23和0.23,这缘于经营范围扩充了有语义词汇库库容,减少了POI企业名称向量化时新词汇特征的损失。因此,采用企业名称+经营范围构建有语义词汇库。
-
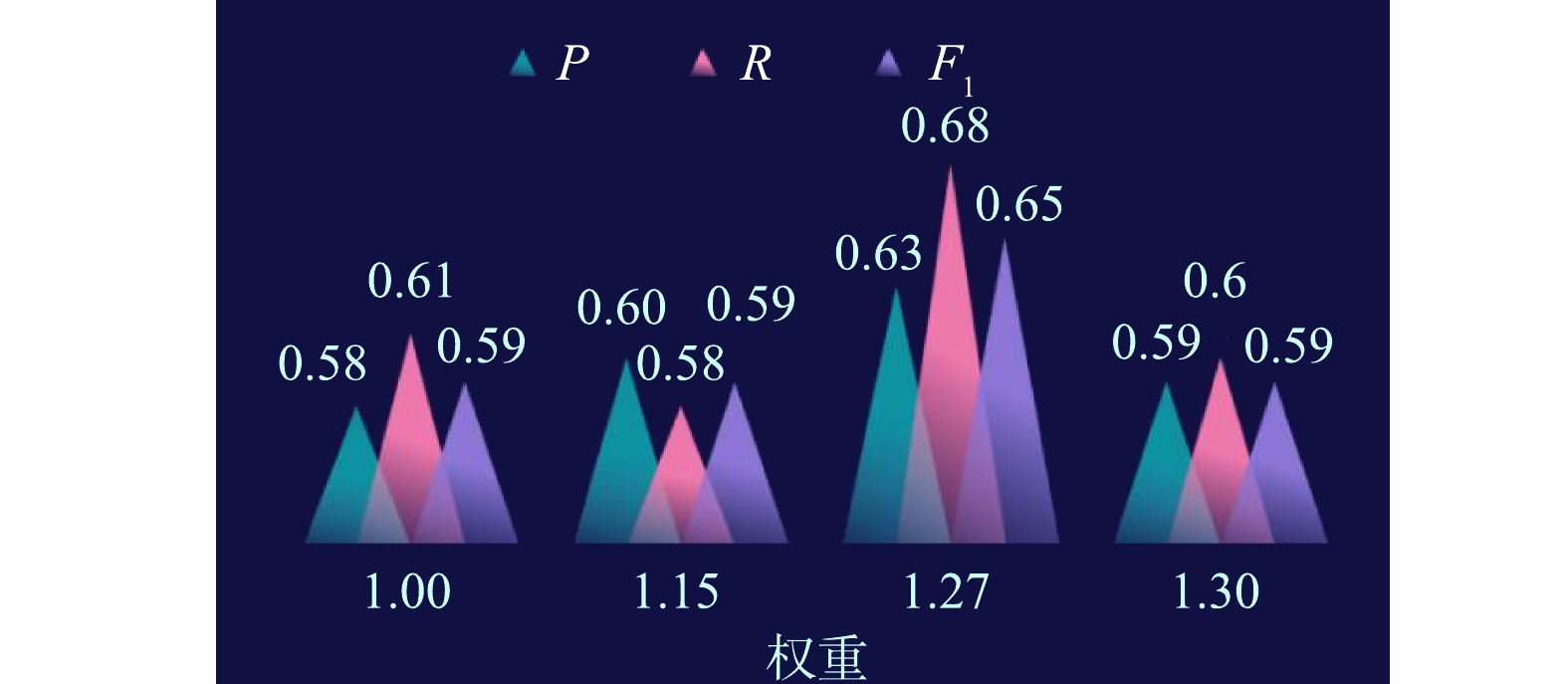
不同权重和平滑参数α分别引起的朴素贝叶斯算法的准确率、召回率和F1值变化见图4和图5。由图4可知,与对照组(权重为1)相比,当权重为1.15和1.30时准确率、召回率和F1值均变化不大;当权重为1.27时三者数值则分别提高了0.05、0.07和0.06,表明权重1.27为最佳值。显然,该最佳值明显提升了具有行业分类特征的特征词的特征值,规避了训练集中各行业样本数分布不均造成朴素贝叶斯算法倾向于大类、忽略小类的现象[21],进而提高了该算法的性能。
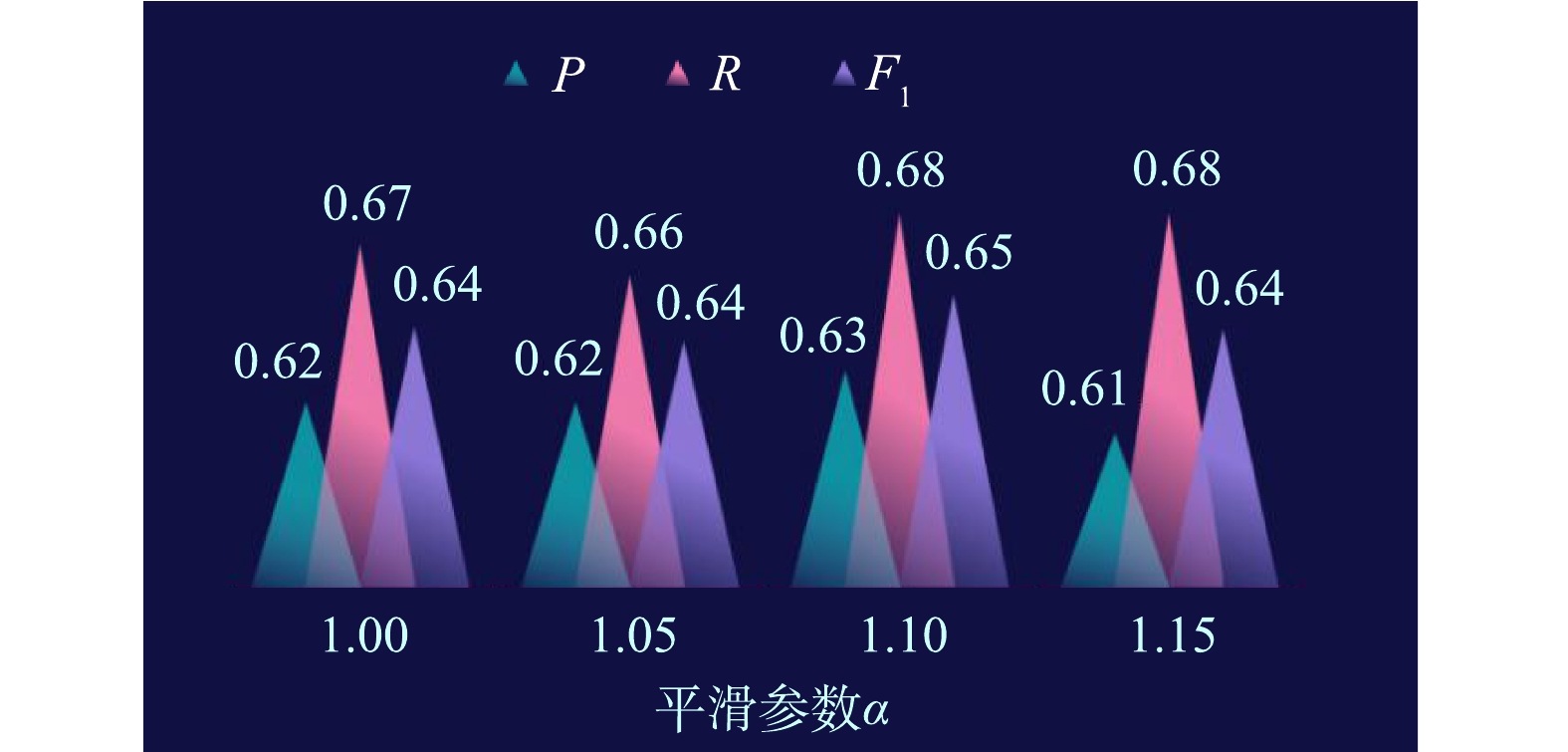
尽管前述利用经营范围扩充了有语义词汇库,但是依然不可能穷举所有的特征词,故在对POI企业名称向量化时仍然会损失新词汇的特征,从而会产生过度拟合现象。另外,在计算先验概率时,若POI企业名称的某个特征词在训练数据集中某个行业类别中没有特征值,则会发生零概率现象[20]。据此,在计算后验概率时,利用平滑参数α力求缓解过度拟合和零概率现象,从而优化朴素贝叶斯算法。由图5可知,当平滑参数α为1.10~1.15时,准确率、召回率和F1值均变化不大,分别为0.61~0.63、0.66~0.68、0.64~0.65;而且,平滑参数α为1.10时,识别效果最好。
-
研究区的POI数据所属疑似土壤污染行业企业的预测结果见表4,相应的POI企业和日常监管企业的空间分布见图6。由表4和图6可知,从行业上看,预测疑似土壤污染行业26个,主要为金属表面处理及热处理加工、铁合金冶炼、专用化学产品制造、农药制造、常用有色金属冶炼、基础化学原料制造和合成材料制造(各行业企业均≥100家);同时,现有日常监管中未关注农药制造(118家)、化学药品原料药制造(1家)、棉纺织及印染精加工(5家)、环境治理业(82家)、皮革鞣制加工(47家)、贵金属冶炼(23家)等行业;从数量上看,识别疑似土壤污染企业1 774家,远远多于日常监管掌握的221家企业;从空间分布上看,各区(市、县)均存在企业集聚区,特别是在A、B、C区的企业分布最为集中。以上结果表明,后续应强化对新识别的行业、企业及其集聚区的土壤污染隐患排查与风险管理。另外,本研究未考虑企业生产规模、生产年限、地块利用历史等因素,对于零星分布的企业同样应做好监管。
2.1. 不同土壤污染重点行业词云
2.2. 行业分类预测算法筛选
2.3. 有语义词汇库构建方法
2.4. 朴素贝叶斯模型优化
2.5. 行业企业空间分布
-
1)在行业分类预测时,朴素贝叶斯算法的性能优于随机森林算法和XGBoost算法的性能。
2)与仅采用企业名称相比,采用企业名称+经营范围构建有语义词汇库后,朴素贝叶斯算法的准确率、召回率和F1值均得到大幅提升,可将其作为最佳的有语义词汇库构建方法。
3)采用权重1.27和平滑参数α为1.10后,建立了改进型朴素贝叶斯模型,相应的准确率、召回率和F1值分别为0.63、0.62和0.63,进而获得了最佳的分类预测性能。
4)利用改性型朴素贝叶斯模型识别出研究区中28个疑似土壤污染行业有关1774家企业,其在各区(市、县)均存在集聚区,特别是在A、B、C区最为集中。
