

 下载:
下载:








-
随着中国经济的高速发展,大气污染成为全社会所关注的问题。当大气污染物达到一定浓度时,会对人体的呼吸系统造成危害,其中PM2.5表现最为明显[1]。因此,对PM2.5浓度的监测及数据获取就显得尤为重要,但目前常用的监测方式均存在一些不足[2],无法实现高分辨率PM2.5浓度空间分布制图。如实验设计监测成本较高、常规监测在监测站数目上得不到保证、车载移动监测的总体监测时间较短等。监测技术的不足为分析城市PM2.5时空分布特征及污染防治带来很大挑战[3],国内外学者尝试通过构建模型的方法来解决问题。黄仁东等[4]利用统计学与多元回归分析法构建四季最优模型,模拟分析了西安市PM2.5污染特征;孙兆彬等[5]利用CMAQ空气质量模型,模拟出兰州市PM10月均浓度;刘杰等[6]应用MATLAB空间插值算法实现对北京市颗粒污染物的空间分布模拟;陈辉等[7]利用MODIS遥感影像反演AOD的方法建立模型,模拟出京津冀地区PM2.5浓度;此外,扩散模型[8]、神经网络[9]等方法也都被应用于大气污染物浓度模拟。然而,这些方法大都未将影响PM2.5浓度的各种因素考虑进去,会对模型模拟结果的解释能力及精度造成影响。LUR模型综合考虑各种影响因素对PM2.5浓度进行模拟,其精度、解释能力较其他方法更强,已成为模拟大气污染物浓度最有效的方法之一[2,10]。
在欧美、日本等国家,LUR模型已被广泛使用,并在模拟城市PM2.5、NO2和NOx等污染物浓度空间分布方面取得良好效果[3,11-13]。我国学者对LUR模型的应用研究不多,多集中于对特定城市污染物浓度的模拟。陈莉等[14]应用该模型模拟了天津市PM10和NO2浓度的空间分布;吴健生等[15]、焦利民等[16]、汉瑞英等[17]及阳海鸥等[18]分别模拟了重庆市、武汉市、杭州市和南昌市的PM2.5浓度空间分布。然而,由于对区域尺度的PM2.5模拟所需数据量大,以及区域城市间污染传输等难题,只有少数学者开展过区域尺度的相关研究[19-20]。
鉴于区域尺度PM2.5的模拟研究对区域联防联控机制有着重要指导意义,本研究以中国西北部关中平原城市群为例,利用LUR模型模拟其PM2.5浓度,探讨LUR模型在区域尺度上的适用性,并进一步构建最优LUR模型,为该区域PM2.5污染防治提供科学依据,也为城市内部PM2.5浓度空间分布数据获取提供新的思路。
全文HTML
-
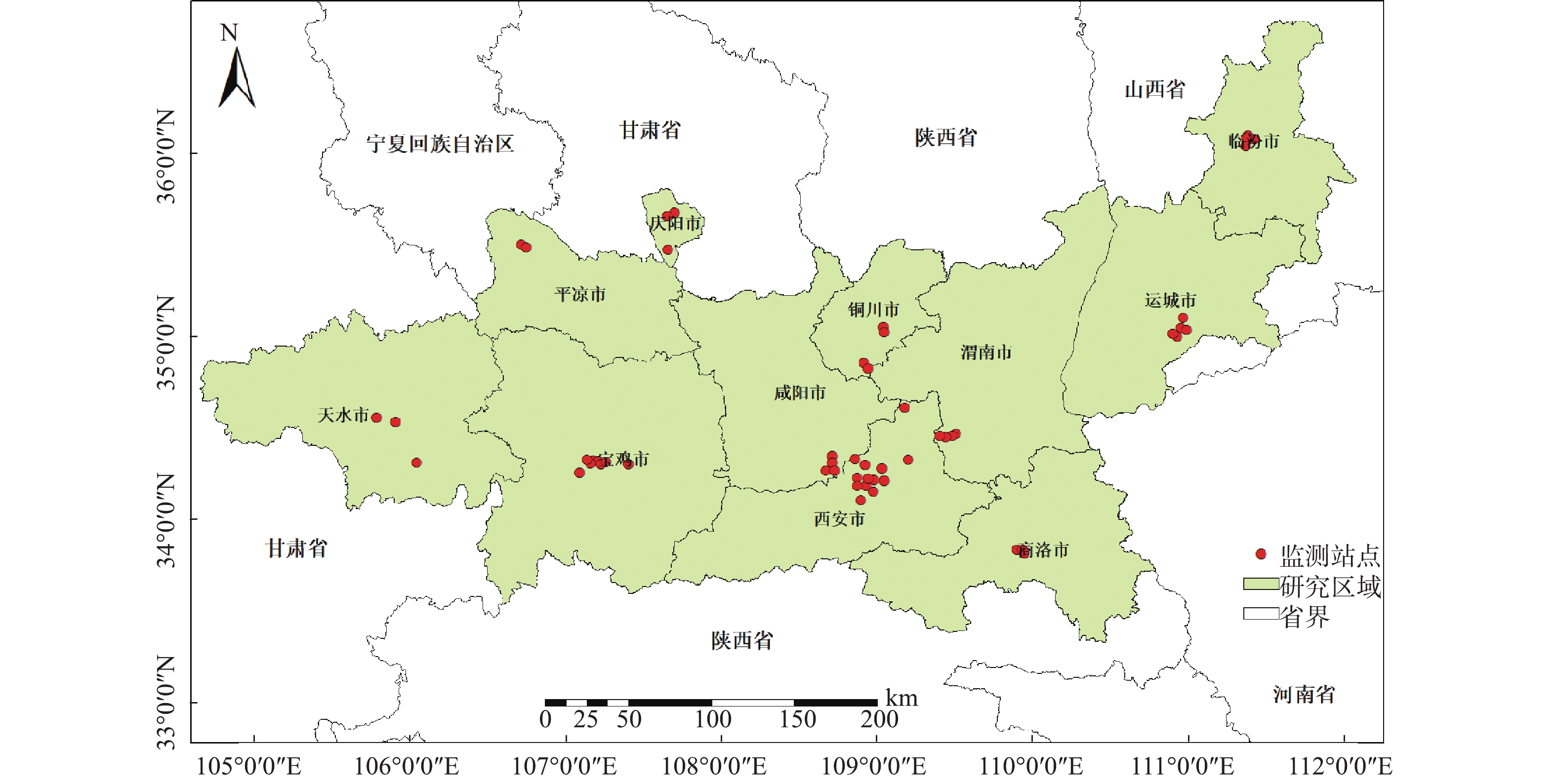
关中平原城市群地处中国内陆中心,是我国雾霾及风沙多发的区域之一,包括西安、咸阳、宝鸡、渭南、铜川、天水以及商洛、临汾、运城、平凉、庆阳的部分区县等。在“一带一路”倡议的推动下,关中平原城市群的综合经济实力已位居中国内陆区域第二,但与此同时,也造成了区域内城市的空气质量恶化。据2017年全国365个城市的年均PM2.5浓度排名显示,该区域有5个城市的年均PM2.5浓度排在了全国前20。区域年平均PM2.5浓度为57.34 μg·m−3,超过国家二级标准60%(35 μg·m−3),空气污染现状不容乐观。
-
LUR具有模拟精度高、考虑因素全面等特点,是模拟PM2.5浓度的有效方法。本研究主要利用SPSS 24.0与Arcgis10.2软件,构建PM2.5浓度与土地利用类型、地形、气象、道路交通、人口密度和污染源等相关因子的多元回归方程,即LUR模型。模型的基本形式通常包括1个因变量和2个或者2个以上自变量,计算方法见式(1)。
式中:y为因变量,即PM2.5浓度值;x1, x2,···,xn为自变量即文中的影响因子;β0,β1,β2,···,βn为待定系数;α为随机变量。
-
首先,利用SPSS软件对PM2.5浓度与各类影响因子进行双变量相关性分析,并筛选去除与PM2.5浓度不显著相关(P>0.05)的影响因子。本研究生成的影响因子包括:土地利用类型(6类)、主要道路交通(4类)、污染源通过生成缓冲区的方式获取77(11×7)个影响因子;气象(5类)、植被指数、高程、人口密度等通过空间插值提取的方式获取8个影响因子,共计得到85(77+8)个影响因子。为避免后续多元线性回归方程中不同缓冲区下同类因子的共线性问题,采用吴健生等[2]提出的后向算法,即先找出每类影响因子中与PM2.5浓度相关性最高的影响因子,然后去除同类因子中与最高影响因子皮尔森相关系数大于0.6的因子。
其次,将筛选后剩余的影响因子与PM2.5浓度值进行逐步线性回归,得到多元线性回归方程,即LUR模型,并采用留一交叉互验(leave-one-out cross validation)的方法对模型精度进行检验。然后利用Arcgis10.2软件生成5 km×5 km规则格网点,根据多元回归方程计算得到每个格网点的PM2.5浓度预测值。
最后,通过克里金插值法(Kriging),模拟出研究区的PM2.5浓度空间分布图。
1.1. 研究区概况
1.2. LUR模型
1.3. 建模方法
-
采集2017年1—12月关中平原城市群范围内共计54个空气质量监测点的日均PM2.5浓度监测数据(数据来自中国环境监测总站http://www.cnemc.cn/),对这些数据进行汇总统计,得到各监测站点年均及季节PM2.5浓度值,研究区范围及监测站点分布,结果如图1所示。
-
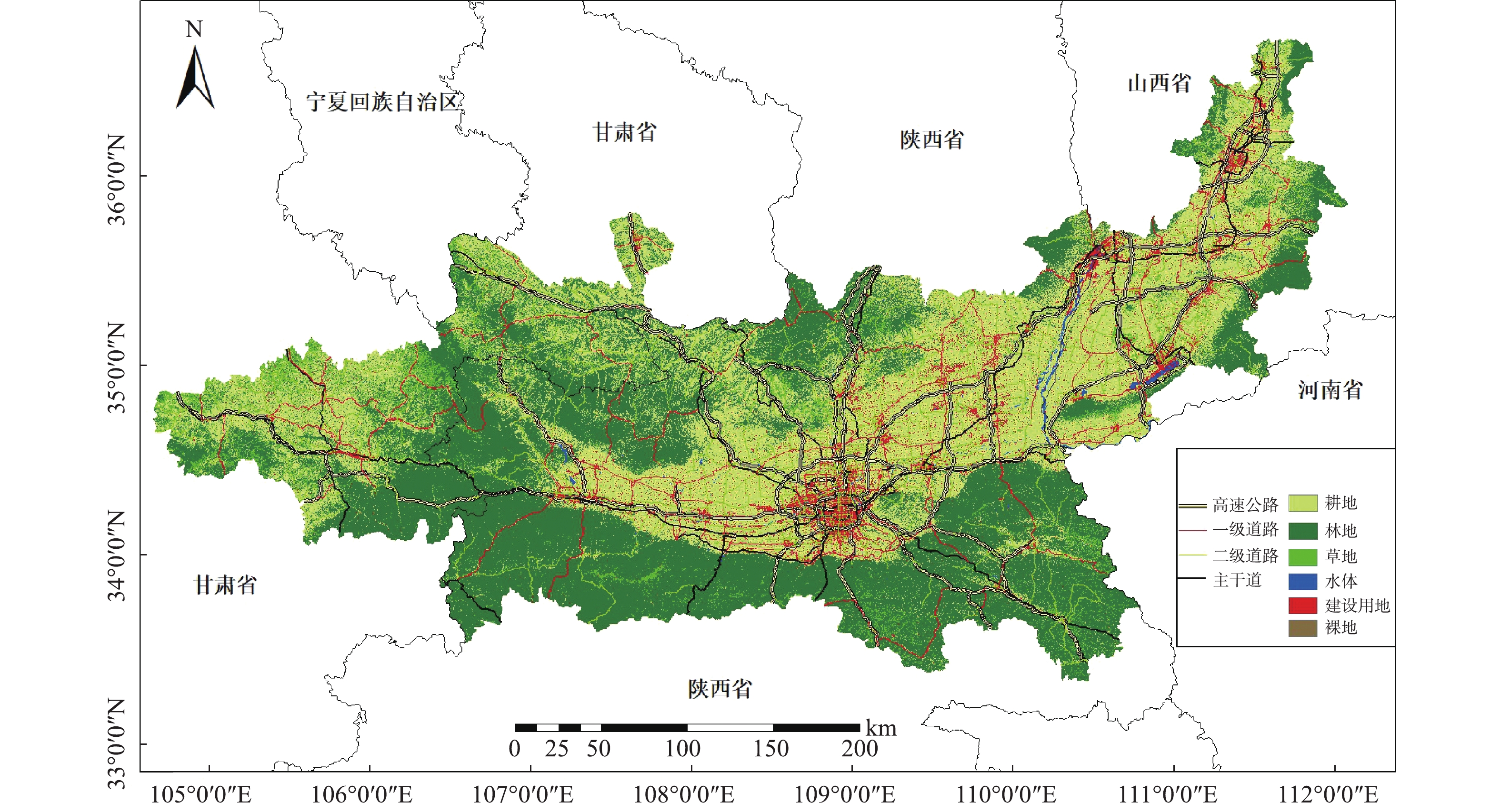
土地利用数据为清华大学发布的2017年全球10 m分辨率土地利用数据集。该数据集将全球土地分为10大类。利用Arcgis10.2经拼接、裁剪和重分类等处理,并考虑各类型用地的面积及属性,将土地利用划分为耕地、林地、草地、水域、建设用地和裸地等6类,结果如图2所示。再以每个监测站点为中心,分别生成0.5、1、1.5、2、3、4和5 km的缓冲区,统计每种缓冲区中各类土地利用类型的面积,将得到的数据作为土地利用类型因子。道路数据来源于OpenStreetMap的矢量路网,提取研究区范围内高速公路、主干道、一级道路、二级道路等4类,并以监测站点为中心建立相同的缓冲区,通过空间叠加法统计得到每种缓冲区内各类道路的长度作为道路因子。
-
关中平原城市群东西海拔相差大,其复杂的地形会对PM2.5浓度产生一定的影响。本研究利用DEM数据表示研究区的地形地貌特征,从地理空间数据云上(http://www.gscloud.cn/)下载获取Aster GDEM数据,经拼接、裁剪得到研究区的DEM,并提取每个监测站点处的高程值作为地形因子。
-
从中国气象科学数据共享服务网,获取研究区范围内28个气象站点2017年的气象数据。选取的气象因子包括:平均大气压、平均降水量、平均气温、平均风速和相对湿度等5项。统计得到各站点气象要素的季节及年均值,并利用空间插值提取的方法,获取各监测站点位置处的气象要素值作为气象因子。
-
归一化植被指数(normalized difference vegetation index, NDVI)数据来源于NASA官方的MODIS数据,选取2017年1月至12月的MOD13A1产品数据。利用MODIS重投影工具 (MODIS reprojection tools, MRT)对该数据进行批量投影、拼接等预处理,然后采取最大值合成法(maximum value composite, MVC)进行数据合成,并裁剪得到研究区年NDVI栅格图,提取监测站点处的NDVI值作为植被指数因子。
-
人口密度数据采用中国科学院资源环境科学数据中心(http://www.resdc.cn/)所发布的2015中国人口分布公里网数据集。以监测站点处的栅格值表示该点的人口密度,作为人口密度因子。工业废气的排放是PM2.5重要来源之一[21-23]。从生态环境部官网上收集到研究区范围内约130个国家重点监测企业(废气)名单及地址信息,再以监测点为中心建立相同的缓冲区,统计每种缓冲区内污染源的个数作为污染源因子。
2.1. PM2.5浓度数据
2.2. 土地利用及道路数据
2.3. 地形数据
2.4. 气象数据
2.5. 植被指数数据
2.6. 人口密度数据与污染源数据
-
以年均PM2.5浓度为例,利用SPSS软件对其与各种影响因子进行双变量相关分析。根据模型筛选变量的方法,首先剔除与PM2.5浓度不显著相关的34个影响因子(P>0.05)。为有效避免后续LUR建模时不同缓冲区下同类影响因子的共线性问题,对自变量进行再次筛选,即先计算出同类影响因子中排序最高因子与其他因子之间的相关系数,然后剔除相关系数大于0.6的影响因子,最终得到16个影响因子。表1数据表明,PM2.5浓度与耕地、林地、水体、草地、裸地、高程、降水量、相对湿度、风速和NDVI等因子呈负相关;与建设用地、气压、温度、人口密度、道路长度和污染源个数等因子呈正相关。其中,PM2.5浓度与高程的相关系数最高,说明研究区PM2.5浓度受高程因素的影响最大。
-
由于各季节气象条件的不同,可能造成影响PM2.5浓度的主导因素不同,故分别以春、夏、秋、冬及年均PM2.5浓度为因变量,同时获取相对应影响因子作为自变量,构建多元回归方程即LUR模型共5个,结果如表2所示。可以看出,最终进入5个LUR模型的影响因子不尽相同。在所有模型当中都包含了高程因子,说明对研究区年均及四季PM2.5浓度影响最大的是地形因素。此外,气象因素中相对湿度因子进入了年均、春和夏季的LUR模型;降水因子分别进入了年均、春、秋和冬季的LUR模型,风速因子则进入了年均及春季的LUR模型。说明在3个气象因子中,降水和相对湿度对研究区的PM2.5浓度影响较大,且对PM2.5浓度有消减作用,而风速对春季的PM2.5影响较大且会使其浓度增加,这与该地区春季扬沙天气频繁密切相关[24];土地利用类型因素中5 km缓冲区内建设用地面积进入了年均及冬季的LUR模型、5 km缓冲区内草地面积和林地面积则分别进入了夏季和秋季的LUR模型。进一步分析模型方程发现,建设用地的增加对PM2.5浓度具有加剧作用,而草地、林地的增加对PM2.5浓度具有削减作用。这是由于土地利用类型的变化会引起地表反射率、粗糙度及植被覆盖度等地表物理性质的改变,从而影响区域内降水、湿度等气象条件,进而导致了PM2.5浓度出现差异[25-26];另一方面也可能与冬季居民区供暖等人为因素有关。由表2中模型调整后的R2可知,5个LUR模型的R2都在0.8以上,表明LUR模型拟合度较好、解释能力较强,其中年均LUR模型R2达到了0.9,在所有模型当中为最好。
采用交叉验证方法对模型的精度进行检验,并通过模型调整后R2、相对误差、均方根误差、线性回归拟合度4项指标,对5种模型的精度及稳定性进行评价。其中相对误差是指模拟值与实测值之间的偏移度,表示的是模型模拟结果的可靠程度;均方根误差是模拟值与实测值之间的偏差,它可以反映模拟结果的准确性;线性回归拟合度则表示模型的拟合精度,计算结果如表3所示。5种模型平均相对误差均值为12%,均方根误差均值为7.37 μg·m−3。对各监测站点的PM2.5浓度预测值与实际值进行线性回归(如图3所示),发现LUR模型的线性拟合度分别为0.85(年均)、0.77(春)、0.81(夏)、0.79(秋)、0.80(冬)。因此,LUR模型在模拟关中平原城市群年均及季节PM2.5浓度时效果较好。经进一步对比,5种模型中年均LUR模型的各项精度指标均为最优,表明LUR模型在模拟研究区年均PM2.5浓度时效果最好,且模拟精度最高、模型最稳定性最强。
-
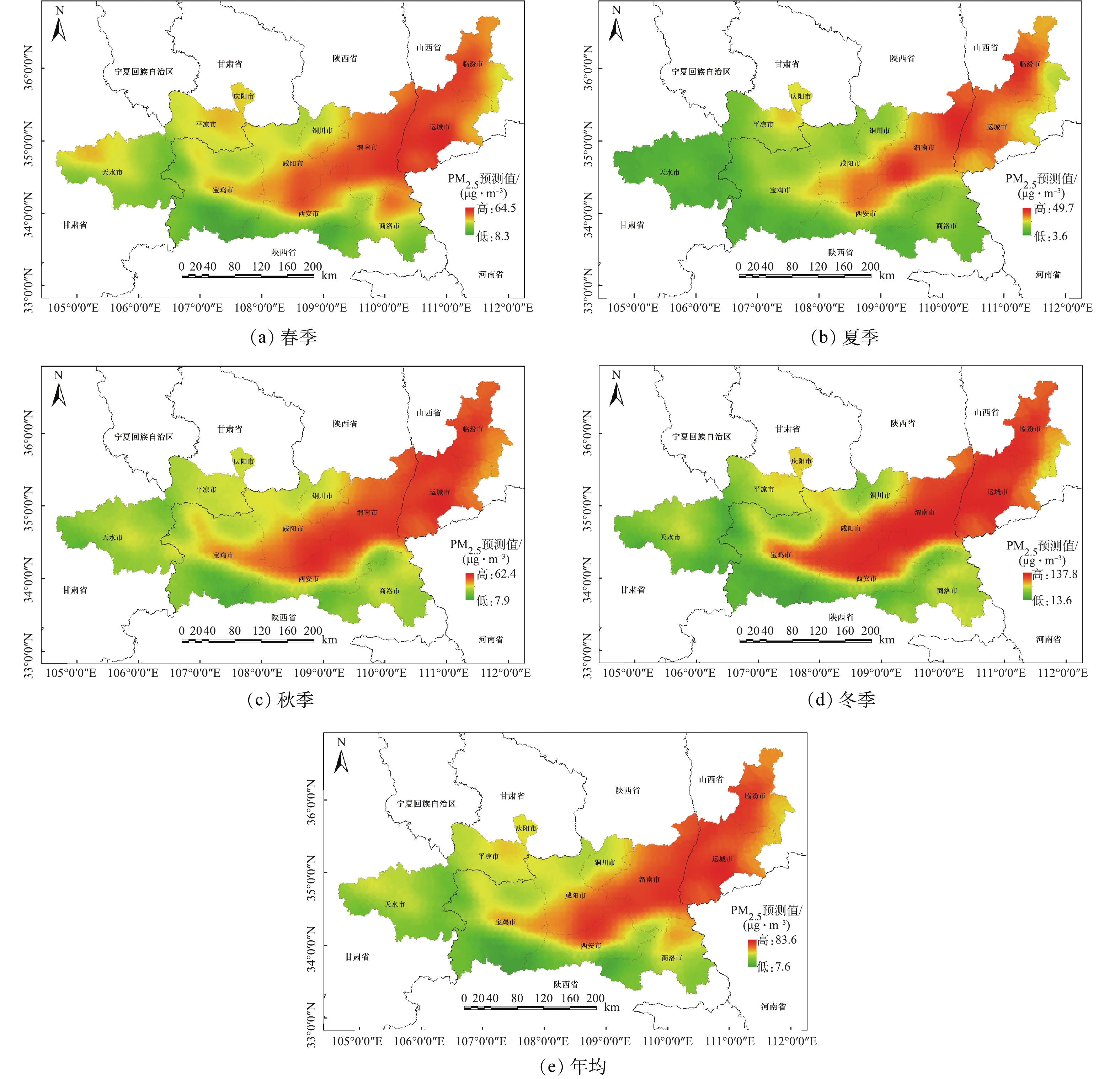
为更加直观地分析关中平原城市群PM2.5空间分布特征,在研究区范围内生成5 km×5 km的格网,并计算出每个格网点相对应的影响因子数值,分别带入表2的多元回归方程式中,得到各格网点的PM2.5浓度值。然后通过采用Kriging插值法,模拟生成关中平原城市群各季节及年均的PM2.5浓度空间分布(图4)。如图4所示,各季节的PM2.5浓度均值变化有明显差异,具体表现为冬季(78.26 μg·m−3)>春季(37.47 μg·m−3)>秋季(34.58 μg·m−3)>夏季(21.28 μg·m−3);另外,PM2.5浓度高值区范围随着季节变化而变化,由夏季的3个污染强点逐渐向四周扩散形成冬季连片状的污染区,这种现象主要由冬季逆温天气多发、建成区内集中供暖等原因所导致[27-28];但各季节的PM2.5空间分布则大致相同,高值大多集中在西安、咸阳、渭南和运城等东部、北部地区,低值则多集中在天水、平凉、宝鸡以及商洛等西部、南部地区;研究区PM2.5浓度沿海拔走势分布明显,关中平原等低海拔的区域污染严重,而秦岭山地等高海拔区域污染较轻。
LUR模型在一定程度上解释了该研究区PM2.5的浓度空间分布特征。研究区内海拔差异明显,地势高低起伏。关中平原中部及东部是人口、城市以及工业生产等主要集中的区域,空气污染相对较重。尤其是晋陕交界一带是煤炭等工业生产活跃的区域。据统计,这一区域内约有国家重点监测企业(废气)55家,大气污染物排放量大,空气污染最为严重。西部及南部地区靠近秦岭山地,植被覆盖度高,加上人口密度小、工业生产活动少等缘故,其空气质量相对较好。
-
1) 完善区域联防联控机制。PM2.5的形成及来源复杂,对单一污染源及单一城市的控制很难从根本上减轻污染。一个城市的大气污染不仅与本地的自然、人为等因素有关,也与外来污染物传输密切相关[29-30]。以该区域重要城市西安为例,有超过50%的气流轨迹来自西北方向[31]。因此,从区域尺度上分析PM2.5空间分布,可进一步为建立完善区域联防联控机制提供可靠的信息支持,以便更好地解决城市大气污染。
2) 实行污染分区监管。根据区域地理特征、气象条件及经济发展等因素的不同,将区域分为严重污染区及一般污染区,实施差异化控制管理,因地制宜地制定污染防治措施。尤其是针对关中平原东部及中部等污染严重的区域,相关政府部门应加快完善预警、约谈、问责工作机制。
3) 实施季节性差异化防治。根据各季节LUR模型当中主要贡献因子的不同,实施有针对性的防治措施。如春夏季可通过道路洒水增加空气湿度减轻污染,据模型显示相对湿度每增加1%,PM2.5浓度会分别降低1.5 μg·m−3和2.3 μg·m−3;秋季可通过人工降雨或增加绿化减轻污染,据模型显示降水量每增加1 mm,PM2.5浓度会降低0.5 μg·m−3;冬季则可通过城区机动车限行、合理供暖以及人工降水降雪等措施减轻污染;模型显示降水量每增加1 mm,PM2.5浓度会降低1.5 μg·m−3。
4) 强化污染源头控制。工业排放及燃煤使用是PM2.5最主要的来源之一,尤其是研究区东部晋陕交界煤炭工业发达,是关中平原大气污染最主要的源头,因此,该区域企业需要加大能源结构调整和节能减排力度,从源头上防治大气污染。
本研究将LUR模型应用到区域尺度的PM2.5浓度空间分布模拟,通过对非监测点PM2.5浓度值的模拟,解决了传统监测方式中站点数量少、覆盖范围小和成本高等问题,并实现了高分辨率PM2.5浓度空间分布制图,且该模型拟合度R2与前人研究结果相比提高了10.3%[15,17],均方根误差相比降低了52%[20]。但由于大气污染物形成机制的复杂性和多样性,模型精度存在一定误差。在针对不同区域和城市的PM2.5浓度分区模拟研究还有待进一步深入;另一方面,目前LUR建模主要以普通线性回归法进行模型构建,考虑的影响因子也通常集中在地形、人口、交通和土地利用类型等方面,这往往会对模型的精确度与解释能力造成负面影响。因此,改进LUR建模方法与扩展LUR模型的自变量也是当前的研究热点,未来可尝试利用神经网络、地理加权回归等方法改进模型,也可考虑将工业污染排放量、人均GDP等与经济相关的自变量因素加入模型,来提高模型的解释能力。
3.1. PM2.5浓度与影响因子相关分析
3.2. 模型构建及精度验证
3.3. PM2.5浓度模拟
3.4. 基于LUR模型的PM2.5污染防治建议
-
1) 相关性分析结果表明,PM2.5浓度与耕地、林地、水体、草地、裸地、高程、降水量、相对湿度、风速和NDVI等呈负相关;与建设用地、气压、温度、人口密度、道路长度和污染源个数等呈正相关,其中高程与PM2.5浓度的相关系数最高。
2) 利用LUR模型模拟了关中平原城市群各季节及年均的PM2.5浓度空间分布,模型调整后R2分别达到0.831 (春)、0.817 (夏)、0.874 (秋)、0.857 (冬)、0.900(全年平均),模型拟合度较好。经精度检验,显示模型平均精度为80.4%,平均相对误差为12%,平均方根误差为7.37 μg·m−3。通过对比,年均LUR模型模拟效果最好。
3) 模拟结果显示,研究区域各季节的PM2.5浓度空间分布呈现出东部高、西部低的明显特征,且其空间分布状况受地形因素的影响较大,浓度高值多集中在关中平原,低值多集中在秦岭山地。此外,各季节的浓度均值变化具有明显的差异性,具体表现为冬季最高、春秋次之、夏季最低。
4) 运用在城市尺度PM2.5浓度模拟的LUR模型,也同样适用于中国西北部关中平原城市群类似的大区域尺度的PM2.5浓度空间分布模拟。经与实际状况相对比,LUR模型在模拟该区域PM2.5浓度时适用性好,精度高,解释能力强。通过模拟分析该研究区的PM2.5浓度空间分布特征,可为当地相关政府部门提供科学合理的PM2.5污染防治建议。
